Data fabrics and data lakes: One platform for universal data storage


Analytics architectures are evolving toward a universal, unified approach that can seamlessly handle diverse workloads across multiple business units. Historically, this architecture was called a data fabric. Data fabrics provide a framework designed to centralize data and unify data architecture for streamlined integration, governance, and accessibility.
With the emergence of open table formats, there is a strong case that data lakes are the ideal foundation for data fabrics. To meet today’s demands, a robust data storage solution must deliver flexibility — including scalability, engine interoperability, and decoupled storage and compute — while also ensuring strong governance and high performance. Data lakes not only feature these capabilities but also offer streamlined data access, reduced total cost of ownership (TCO), and the ability to break down silos, enabling both powerful analytics and AI applications.
[CTA_MODULE]
Data lakes are undergoing a renaissance
While data lakes have been around for years, the ability to seamlessly combine them with table-level governance and structure is a more recent development. Traditional data lakes offered flexible, large-scale storage but suffered from significant drawbacks — minimal data structures beyond files and folders, difficult querying because of the lack of a higher-level concept than a folder/file, and poor data inventory management.
Cloud data warehouses emerged to address many of these issues for analytical workloads, offering higher levels of abstraction over the full data lifecycle management, which resulted in greater ease of use. However, warehouses struggle to handle unstructured data essential for AI and ML, and they become cost-prohibitive at scale. For a long time, this split investment between data warehouses and AI/ML analytics tools. Data lakes were unwieldy, warehouses were expensive, and data was often duplicated across both.
The renaissance of data lakes — driven by open table formats — has changed the equation. These formats bring robust data management, compliance capabilities, and interoperability with warehouses, catalogs, and other modern data stack tools, while still delivering scalable, affordable storage for massive datasets.
Old, fragmented data stacks can be complex and costly
Old data stacks, combining data warehouses and data lakes in parallel, posed several problems
The challenges emerging from these architectural choices create several obstacles:
First is compliance. Having to duplicate your data into different formats just to “gain access” to specific features adds a significant compliance burden. Compliance concerns are on the rise with the number of data handling regulations increasing. As data becomes scattered across multiple systems for different use cases, ensuring compliance becomes increasingly challenging.
The second challenge is vendor lock-in. Even with the adoption of multiple platforms, your data is still stored in each of these platforms, often requiring different data formats. Switching between formats slows you down and limits your ability to choose the best platform for each team and their use case.
And then there's the rising total cost of ownership. Organizations have onboarded numerous technologies for specific needs without consolidation. Now, they’re starting to feel the financial pinch of maintaining a large and fragmented tech stack, especially as data volumes increase with AI use cases.
With the duplication of data across multiple data warehouses, costs (especially related to ingest compute) and complexity multiply. Many enterprises in the last decade have assembled complicated architectures featuring separate tools for data analysis and machine learning in an attempt to get access to the best features of each platform provider. Unfortunately, this has resulted in costly, administratively complex data architectures.
The modern solution: A universal storage layer
The challenges of compliance, vendor lock-in, and rising costs highlight the need for innovative solutions to manage data effectively and efficiently.
Your data fabric foundation should accommodate every data use case by leveraging the capabilities of modern data lakes. The key enabling technology is the open table format. With data catalog integration, teams can also manage and govern data effectively.
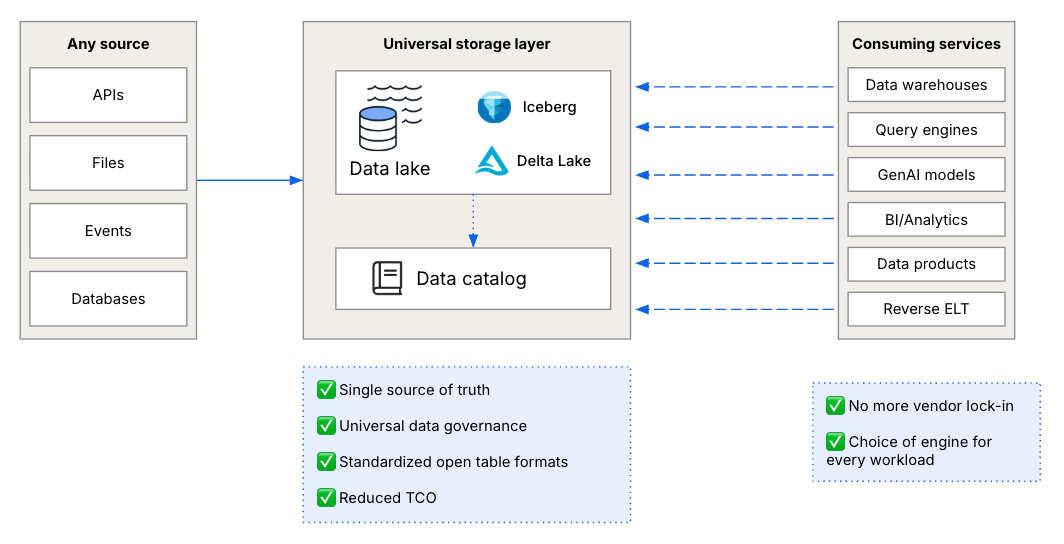
Data lakes explicitly separate the storage layer of the analytics stack into a separate, vendor-neutral format in object storage to create a universal storage layer. This approach ensures you only move your data once, but can query as needed from engines suited to each unique use case. Multiple, specialized execution engines can interact with the same data lake, mediated by a catalog that provides transactional guarantees.
This architecture overcomes many of the challenges we just discussed:
- Single source of truth - reduced copies of data
- Universal data governance in a central storage layer
- Standardized, interoperable formats
- No more vendor lock-in
- Reduced TCO from having a streamlined data storage strategy
This modern data lake architecture delivers true separation of storage and compute. However, a data lake is not necessarily simple or straightforward to administer. Data integration, the ongoing maintenance of files in an open table format, and other tasks can easily consume valuable technical effort.
The Fivetran solution: The Managed Data Lake Service
Fivetran has taken a unique approach to data lakes — building a managed data lake service to make this architecture one that enterprises can rely on to be managed, scalable, and cost-effective now and in the future.
The Fivetran Managed Data Lake Service combines the best of all worlds, delivering data warehouse functionality such as ACID-compliant transactions and data abstraction of tables alongside the massive scalability and cost efficiency of data lakes.
Fivetran writes the data to Parquet files and automatically applies the appropriate metadata for Iceberg or Delta Lake before committing the transaction to the catalog, where it can immediately be queried. The Delta Lake and Iceberg formats enforce ACID properties, offering consistent representations of your data. The data in your managed data lake arrives in a transactionally consistent way even with change data syncs. Our implementation handles complex change data capture (CDC) processing with ease while also maintaining table health. Data is cleansed, normalized, and de-duplicated per automated processes when it’s ingested. Fivetran incurs the cost of this ingestion (typically 20-30% of compute).
Paired with native integrations with cloud data catalogs like AWS Glue, Unity Catalog, and BigQuery metastore, users get to decide where they want to surface and manage their data lake tables.
The Managed Data Lake Service also regularly performs table and file maintenance to optimize storage — all in a single, integrated solution. Fivetran performs clean up and table maintenance on the managed destination. We clean up orphan files every 14 days and expire old snapshots weekly.
In addition, the Managed Data Lake Service features other standard Fivetran capabilities:
- 700+ prebuilt connectors for SaaS apps, databases, event streams, and files, each of which can be tried for free for a period of 14 days
- Support for custom data sources through an SDK that can readily be combined with AI copilots
- Change data capture (CDC) for real-time, incremental updates
- Automated schema drift handling — no manual intervention required
- Built-in transformations with dbt-native workflows
- Support for data warehouses, data lakes, and vector databases as destinations
- Support for reverse ETL and data activation
- Global infrastructure with 24/7 support and SLAs
- Enterprise-grade compliance: SOC 2, HIPAA, PCI
- High uptime, ensured by a 500+ strong engineering and global support teams
Together, these capabilities allow teams to center their entire data architecture around the data lake, building centralized, unified data fabric.
Customer experiences with the Managed Data Lake Service
One organization that successfully built a data fabric with Fivetran is Interloop, a data infrastructure and analytics firm. Interloop not only lowered data extraction costs and storage overhead using Fivetran Managed Data Lake Service for Microsoft OneLake, but also cut analytics project turnaround time by over 50%, enabling faster decision-making and business responsiveness.
Similarly, marketing agency Tinuiti sped up onboarding by 120x (from weeks to under an hour), slashed maintenance overhead, and enabled self‑service connectors for 80% of sources. By automating open‑table format conversion and metadata management, Tinuiti could switch from a data warehouse to a modern data lake, improving ingest performance, cost efficiency, and governance, and paving the way for AI‑driven marketing insights.
By combining the functionality of a data warehouse with the flexibility of a data lake, the Fivetran Managed Data Lake Service enabled a true data fabric for these two companies.
Governing the data lake is key to the data fabric
The Fivetran Managed Data Lake Service transforms data lakes from a storage bucket to a governed data store, overcoming the following challenges, ultimately enabling your data team to have a greater ROI:
- Compliance: landing data in a universal storage layer that can be queried without the need for data duplication, centralizes and streamlines data governance
- Query-ready data: by converting data into open table formats it can be queried by the query engine of your choice
- Lower costs: with a universal storage layer where Fivetran incurs the cost of ingesting data into your data lake so your budget can be spent on higher value initiatives
As data use cases grow in diversity and importance, the data fabric will only become more critical. Unified, centralized data architectures that can accommodate every data use case are the future, and the Fivetran Managed Data Lake Service can help you thrive in it.
[CTA_MODULE]
Articles associés
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.










