

PARTAGER
Un data pipeline est une série d’actions permettant de combiner les data provenant de plusieurs sources à des fins d’analyse ou de visualisation.
Dans le paysage commercial actuel, le fait de prendre des décisions intelligentes rapidement est un avantage concurrentiel essentiel. Cependant, exploiter les informations tirées de vos data d’entreprise en temps opportun peu sembler être un véritable casse-tête. Le volume des data (et des sources de data) augmente chaque jour : solutions locales, applications SaaS, databases et autres sources de data externes. Comment est-il possible de rassembler les data issues de toutes ces sources disparates ? Grâce aux data pipelines.
Qu’est-ce qu’un data pipeline ?
Un data pipeline est un ensemble d’actions et de technologies qui acheminent des data brutes d’une source vers une destination. Les data pipelines sont parfois appelés connecteurs de data.
Les data pipelines se composent de trois éléments : une source, une étape de transformation de data et une destination.
- Une source de data peut être une database interne comme une database transactionnelle de production optimisée par MongoDB ou PostgreSQL, une plateforme cloud telle que Salesforce, Shopify ou MailChimp, ou une source de data externe telle que Nielsen ou Qualtrics.
- La transformation de data peut être réalisée à l’aide d’outils comme dbt ou Trifacta, ou bien être construite manuellement à l’aide d’un mélange de technologies telles que Python, Apache Airflow et d’autres outils similaires. Ces outils sont principalement utilisés pour rendre les data provenant de sources externes pertinentes pour chaque cas d’utilisation commercial unique.
- Les destinations sont les référentiels dans lesquels les data sont stockées après extraction, par exemple les data warehouses ou les data lakes.
Les data pipelines vous permettent de centraliser les data provenant de sources disparates vers un seul emplacement à des fins d’analyse. Ainsi, vous pouvez obtenir un aperçu plus complet de vos clients, créer des tableaux de bord financiers consolidés, et bien plus encore.
Par exemple, la pile marketing et de vente d’une entreprise peut inclure des plateformes distinctes telles que Facebook Ads, Google Analytics et Shopify. Si un analyste de l’expérience client souhaite donner un sens à ces points de data afin de comprendre l’efficacité d’une publicité, il a besoin d’un pipeline de data pour gérer le transfert et la normalisation des data de ces sources disparates vers un data warehouse, par exemple Snowflake.
En outre, les data pipelines peuvent transférer les data depuis un data warehouse ou un data lake vers des systèmes opérationnels, tels qu’un système de traitement de l’expérience client comme Qualtrics.
Les data pipelines permettent également de garantir une qualité de data cohérente, ce qui est un élément indispensable pour une informatique décisionnelle fiable.
Architecture du data pipeline
De nombreuses entreprises modernisent leur infrastructure de data en adoptant des outils cloud native. Les data pipelines (ou pipelines de données) automatisés représentent un composant essentiel de cette pile de data moderne et permettent aux entreprises d’adopter de nouvelles sources de data tout en améliorant l’informatique décisionnelle.
La pile de data moderne se compose des éléments suivants :
- Un outil d’automatisation du pipeline de data comme Fivetran
- Une destination data cloud telle que Snowflake, Databricks Lakehouse, BigQuery ou AWS Redshift
- Un outil de transformation post-chargement tel que dbt (aussi connu sous le nom d’outil de construction de data, par Fishtown Analytics)
- Un système de business intelligence comme Looker, Chartio ou Tableau
Les data pipelines permettent de transférer les data d’une plateforme source vers une destination, dans laquelle les data peuvent être consommées par les analystes et les data scientists puis transformées en informations utiles.
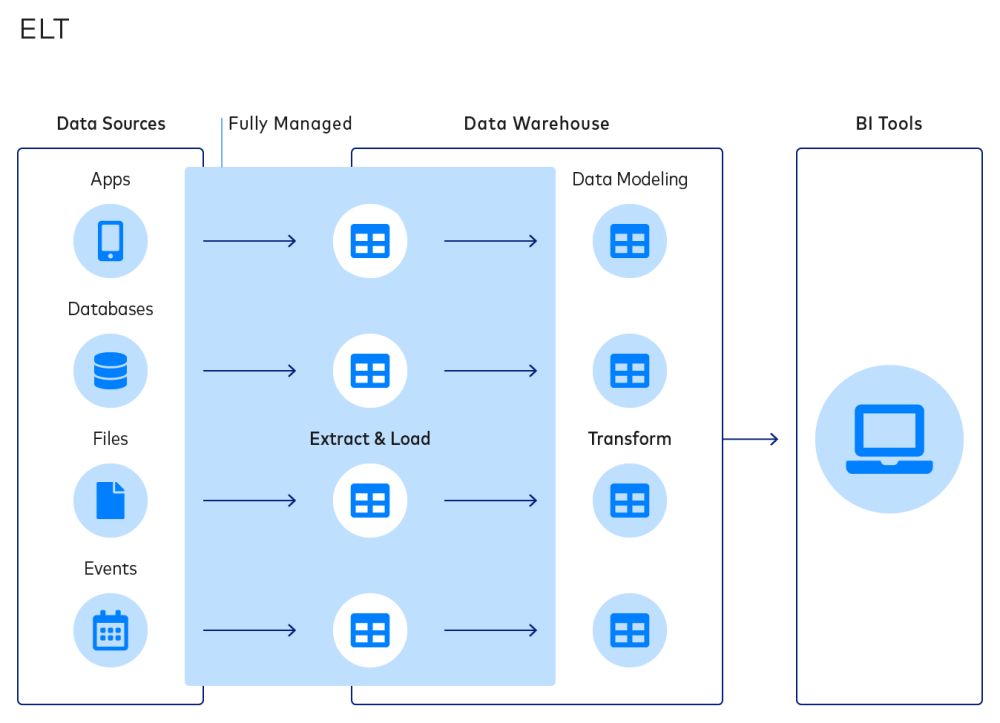
Prenons l’exemple du fabricant de chaussures de sport ASICS. L’entreprise avait besoin d’intégrer les data de NetSuite et Salesforce Marketing Cloud vers Snowflake afin d’obtenir un aperçu complet de ses clients.
Pour ce faire, l’équipe data ASICS a examiné les data de ses applications principales, dans ce cas l’application populaire Runkeeper, et les data combinées sur les inscriptions aux programmes de fidélité, ainsi que des data provenant d’autres canaux d’attribution. Grâce à un data pipeline, ASICS a pu faire évoluer facilement son intégration de data.
Il existe de nombreuses variantes au flux de travail présenté ci-dessus, qui dépendent du cas d’utilisation et de la destination choisie par l’entreprise.
Les étapes de base du transfert de data comprennent :
1 : Lecture à partir d’une source
Les sources peuvent inclure des databases de production telles que MySQL, MongoDB et PostgreSQL, ainsi que des applications Web comme Salesforce et MailChimp. Un pipeline de data lit les data du point de terminaison de l’API à des intervalles réguliers.
2 : Définition d’une destination
Les destinations peuvent inclure un data warehouse cloud (Snowflake, Databricks Lakehouse, BigQuery ou Redshift), un data lake ou un système de business intelligence ou de tableaux de bord.
3 : Transformation de data
Les professionnels des data ont besoin de data structurées et accessibles qui peuvent être interprétées de manière à faire sens pour les partenaires commerciaux. La transformation de data permet aux professionnels de modifier les data et de les formater afin qu’elles soient pertinentes et significatives pour leur cas d’utilisation commercial spécifique.
La transformation de data peut prendre plusieurs formes, par exemple :
- Transformation constructive : ajout, copie ou réplication de data
- Transformation destructive : suppression de champs, d’enregistrements ou de colonnes
- Transformation esthétique : normalisation des salutations, des noms de rue, etc. (aussi appelé nettoyage de data)
Les transformations permettent d’obtenir des data bien organisées au bon format, faciles à interpréter pour les applications et les humains. Un analyste de data peut utiliser un outil tel que dbt pour normaliser, trier, valider et vérifier les data importées à partir du pipeline.
Fiabilité du data pipeline et de l’ETL
Comme tout ce qui à trait à la technologie, les systèmes tombent en panne, et cela concerne aussi les flux de data. Lorsque vos opérations de business intelligence et d’analyse de data reposent sur des data extraites à partir de différentes sources, il est préférable que vos pipelines de data soient rapides et fiables. Mais lorsque vous ingérez les data de sources externes telles que Stripe, Salesforce ou Shopify, les modifications d’API peuvent entraîner des champs supprimés ou des flux de data défectueux.
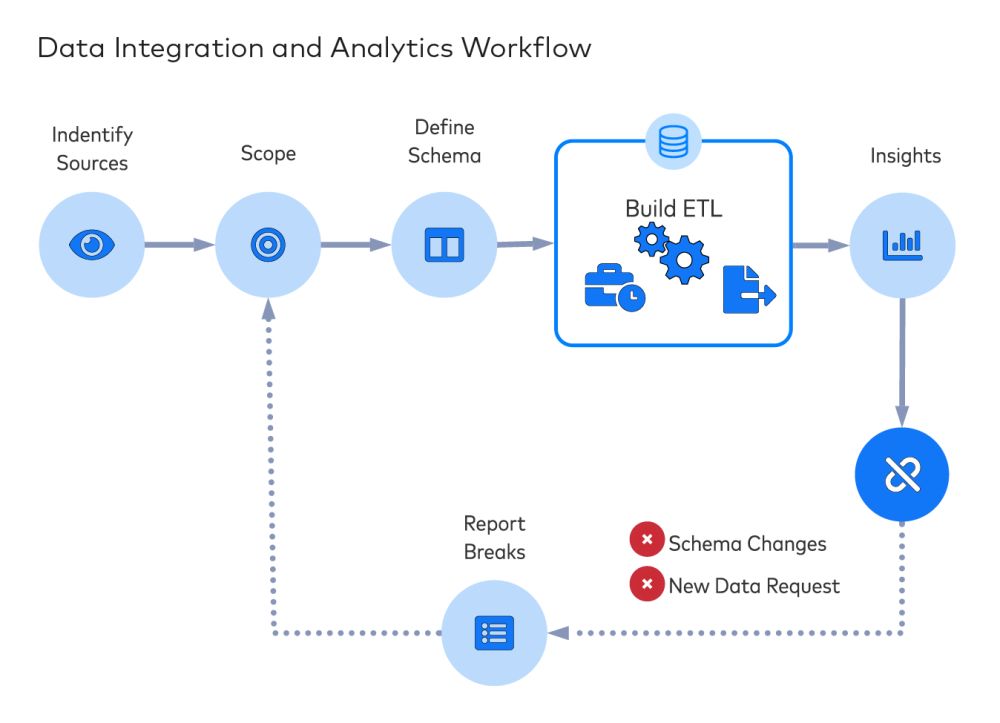
En outre, la construction d’un pipeline de data dépasse souvent les capacités techniques (ou les souhaits) des analystes. Cela nécessite généralement l’implication étroite des talents informatiques et d’ingénieurs, ainsi que du code sur mesure permettant d’extraire et de transformer chaque source de data. Les data pipelines exigent de la maintenance et de l’attention, par exemple pour les « pipelines qui fuient » : des pipelines dans lesquels les entreprises investissent de l’argent sans grand résultat en retour. Ne pensez même plus à la complexité liée à la construction d’un pipeline de data indempotent.
Avec la croissance rapide des options basées sur le cloud et la chute des coûts du cloud computing et du stockage cloud, il n’y a plus beaucoup de raisons de continuer cette pratique. Aujourd’hui, il est possible de conserver de gros volumes de data dans le cloud à faible coût, ainsi que d’utiliser un outil de pipeline de data SaaS pour améliorer et simplifier l’analyse de data.
En bref, vous pouvez désormais extraire et charger les data (dans le cloud), puis les transformer selon vos besoins en matière d’analyse. Si vous hésitez entre l’ETL et l’ELT, optez pour l’ELT.
Connecteurs de data automatisés
Vos ingénieurs data peuvent sans aucun doute créer des connecteurs afin d’extraire des data de diverses plateformes. Mais avant de créer vos propres connecteurs de data, passez en revue nos considérations sur l’achat ou la création de pipelines de data. Le coût varie selon les régions et les échelles de rémunération, mais vous pouvez effectuer rapidement quelques calculs et décider si les efforts et le risque en valent la peine.
Les ingénieurs data préfèrent se concentrer sur des projets de plus haut niveau plutôt que sur le déplacement de data d’un point A vers un point B, sans parler de l’entretien des « pipelines qui fuient » mentionnés plus haut.
Comparez les efforts nécessaires à la création manuelle de connecteurs par rapport à l’utilisation d’un outil de pipeline de données automatisé. Ce type d’outil surveille les sources de data pour détecter les modifications de toute nature et peut ajuster automatiquement le processus d’intégration de data sans impliquer les développeurs.
C’est pourquoi les connecteurs de data automatisés constituent le moyen le plus efficace pour réduire la charge de travail des programmeurs et favoriser le travail des analystes de data et des data scientists.
Lorsque le transfert de data (ou les pipelines de data) sont gérés, les ingénieurs de data peuvent jouer un rôle plus utile et plus intéressant : cataloguer les data pour les parties prenantes internes et faire office de pont entre l’analyse et la science des data.
Pourquoi choisir Fivetran ?
Les connecteurs automatisés de Fivetran sont pré-construits et pré-configurés. Ils prennent en charge plus de 150 sources de data, notamment des databases, des services cloud et des applications. Les connecteurs Fivetran s’adaptent automatiquement à mesure que les fournisseurs modifient leurs schémas en y ajoutant ou supprimant des colonnes, changent des types d’élément de data ou ajoutent de nouveaux tableaux. Enfin, nos pipelines gèrent la normalisation et créent des ressources de data prêtes à être interrogées pour votre entreprise, qui tolèrent les erreurs et disposent de capacités de récupération automatique en cas d’échec. Découvrez plus d’informations sur nos solutions d’intégration de data automatisées.
Free eBook: Build vs Buy Data Pipeline Guide
DOWNLOADStart your 14-day free trial with Fivetran today!
Get started today to see how Fivetran fits into your stackShare
Articles associés
Commencer gratuitement
Rejoignez les milliers d’entreprises qui utilisent Fivetran pour centraliser et transformer leur data.
Merci ! Votre soumission a bien été reçue !
Oups ! Une erreur est survenue lors de l'envoi du formulaire.









