

Teilen
Eine Data Pipeline ist eine Reihe von Aktionen, über die Daten aus mehreren Quellen zu Analyse- oder Visualisierungszwecken kombiniert werden.
In der geschäftlichen Landschaft von heute stellt das schnellere Treffen intelligenterer Entscheidungen einen essenziellen Wettbewerbsvorteil dar. Doch die Nutzung zeitnaher Erkenntnisse, die aus Ihren Unternehmensdaten gewonnen wurden, kann wie eine ziemlich problematische Herausforderung wirken. Die Datenmenge – und die Anzahl der Datenquellen – wachsen jeden Tag: On-Prem-Lösungen, SaaS-Anwendungen, Datenbanken und andere externe Datenquellen. Wie können Sie die Daten aus all diesen separaten Quellen zusammenführen? Data Pipelines.
Was ist eine Data Pipeline?
Eine Data Pipeline ist eine Reihe von Aktionen und Technologien, die Rohdaten von einer Quelle in ein Ziel übertragen. Data Pipelines werden manchmal auch als Data Connectors bezeichnet.
Data Pipelines setzen sich aus drei Bestandteilen zusammen: einer Quelle, einem Datentransformations-Schritt und einer Destination.
- Eine Datenquelle könnte beispielsweise eine interne Datenbank wie eine über MongoDB oder PostgreSQL betriebene produktionsbezogene Transaktionsdatenbank sein oder eine Cloud-Plattform wie Salesforce, Shopify oder MailChimp oder eine externe Datenquelle wie Nielsen oder Qualtrics.
- Die Datentransformation ist über Tools wie dbt oder Trifacta möglich oder kann mit einer Mischung von Technologien wie Python, Apache Airflow und ähnlichen Tools manuell erstellt werden. Diese Tools werden in erster Linie verwendet, um Daten aus externen Quellen für die jeweiligen einzigartigen geschäftlichen Anwendungsfälle relevant zu machen.
- Destinations sind die Verzeichnisse, in denen Daten nach dem Extrahieren gespeichert werden, beispielsweise Data Warehouses oder Data Lakes.
Data Pipelines bieten Ihnen die Möglichkeit, Daten aus verteilten Quellen zu Analysezwecken an einem Ort zu zentralisieren. Sie können eine robustere Sicht auf Ihre Kunden erhalten, zusammengeführte Finanz-Dashboards erstellen und mehr.
Beispielsweise könnte der Marketing- und Handelsstack des Unternehmens separate Plattformen wie Facebook Ads, Google Analytics und Shopify umfassen. Wenn ein Analyst für das Kundenerlebnis diese Datenpunkte betrachten möchte, um die Effektivität einer Werbeanzeige zu verstehen, ist dafür eine Data Pipeline für den Transfer und die Normalisierung der Daten aus diesen verteilten Quellen in einem Data Warehouse wie Snowflake erforderlich.
Darüber hinaus können Data Pipelines Daten aus einem Data Warehouse oder Data Lake in operative Systeme einspeisen, etwa in ein Kundenerlebnis-Verarbeitungssystem wie Qualtrics.
Data Pipelines können auch eine konstante Datenqualität gewährleisten, was für eine verlässliche Business Intelligence von zentraler Bedeutung ist.
Architektur der Data Pipeline
Viele Unternehmen modernisieren ihre Dateninfrastruktur durch die Einführung cloudnativer Tools. Automatisierte Data Pipelines sind eine essenzielle Komponente dieses Modern Data Stacks und bieten Unternehmen die Möglichkeit, neue Datenquellen zu nutzen und die Business Intelligence zu optimieren.
Der Modern Data Stack umfasst:
- Ein automatisiertes Data Pipeline-Tool wie Fivetran
- Eine Cloud-Daten-Destination wie Snowflake, Databricks Lakehouse, BigQuery oder AWS Redshift
- Ein Tool für die Transformation nach dem Laden wie dbt (auch bekannt als Data Build Tool von Fishtown Analytics)
- Eine Business Intelligence-Engine wie Looker, Chartio oder Tableau
Data Pipelines ermöglichen den Transfer von Daten von einer Quellplattform zu einer Destination, wo die Daten von Analysten und Datenwissenschaftlern genutzt und in wertvolle Erkenntnisse umgewandelt werden können.
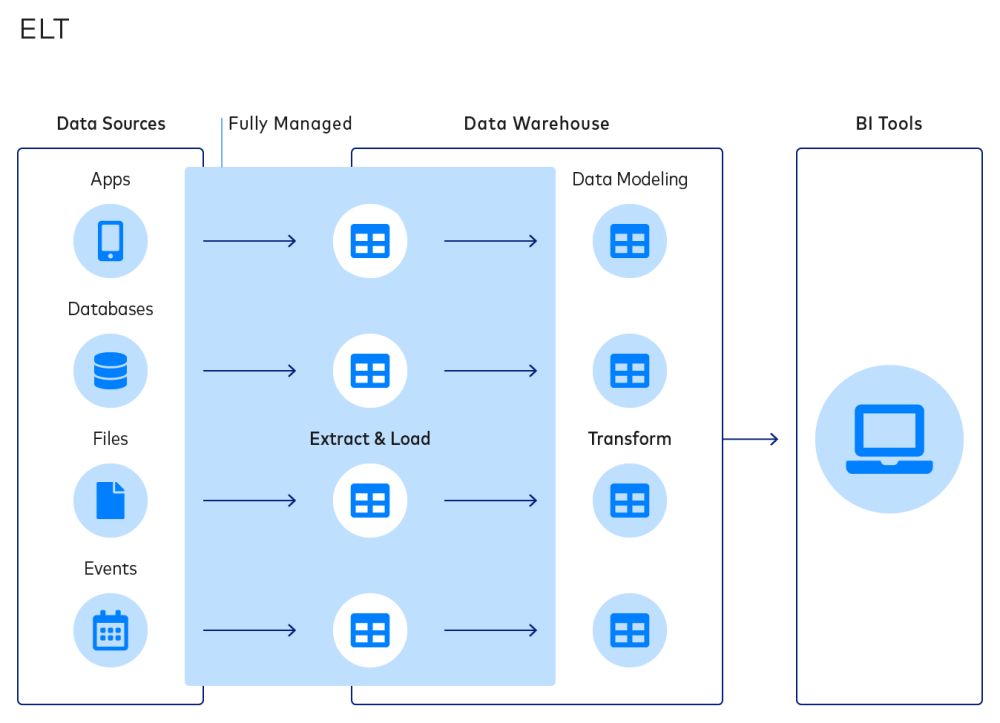
Sehen wir uns als Beispiel den Fall des Laufschuh-Herstellers ASICS an. Das Unternehmen musste Daten aus NetSuite und Salesforce Marketing Cloud in Snowflake integrieren, um so eine 360-Grad-Sicht seiner Kunden zu erhalten.
Um dies zu bewerkstelligen, betrachtete das Datenteam von ASICS seine wesentlichen Anwendungsdaten – in diesem Fall aus der beliebten App Runkeeper – und kombinierte die Daten zu Anmeldungen für Treueprogramme mit Daten aus anderen Attributionskanälen. Mit einer Data Pipeline konnte ASICS seine Datenintegration einfach skalieren.
Für den oben beschriebenen Workflow gibt es viele verschiedene Ansätze, die vom geschäftlichen Anwendungsfall und der bevorzugten Destination abhängen.
Die grundlegenden Schritte der Datenübertragung umfassen:
1: Lesen aus einer Quelle
Die Quellen können Produktionsdatenbanken wie MySQL, MongoDB und PostgresSQL sowie Web-Anwendungen wie Salesforce und MailChimp sein. Eine Data Pipeline liest die Daten in festgelegten Intervallen aus dem API-Endpoint.
2: Definieren einer Destination
Destinations können ein Cloud Data Warehouse (Snowflake, Databricks Lakehouse, BigQuery oder Redshift), einen Data Lake oder eine Business Intelligence-/Dashboarding-Engine umfassen.
3. Transformieren von Daten
Datenexperten benötigen strukturierte und zugängliche Daten, die einfach interpretiert werden können und somit auch für Geschäftspartner Sinn ergeben. Die Datentransformation bietet dem Nutzer die Möglichkeit, die Daten und deren Format anzupassen und für den spezifischen geschäftlichen Anwendungsfall relevant und verständlich zu machen.
Die Datentransformation kann viele Formen annehmen, zum Beispiel:
- Konstruktiv: Hinzufügen, Kopieren oder Replizieren von Daten
- Destruktiv: Löschen von Feldern, Datensätzen oder Spalten
- Ästhetisch: Standardisierung von Grußformeln, Straßennamen usw. (auch als Datenbereinigung bezeichnet)
Durch Transformationen werden die Daten in ein organisiertes Format gebracht – und sind somit für Menschen und Anwendungen leichter zu interpretieren. Datenanalysten können Tools wie dbt verwenden, um die über die Pipeline herangezogenen Daten zu standardisieren, zu sortieren, zu validieren und zu verifizieren.
Verlässlichkeit von ETL und der Data Pipeline
Wie immer in der Welt der Technologie kann es vorkommen, das etwas beschädigt wird. Datenflüsse sind da keine Ausnahme. Wenn sich Ihre Data Analytics- und Business Intelligence-Abläufe auf Daten aus verschiedenen Quellen verlassen, benötigen Sie unbedingt schnelle und verlässliche Data Pipelines. Wenn Sie jedoch Daten aus externen Quellen wie Stripe, Salesforce oder Shopify integrieren, können API-Änderungen zu gelöschten Feldern und beeinträchtigten Datenflüssen führen.
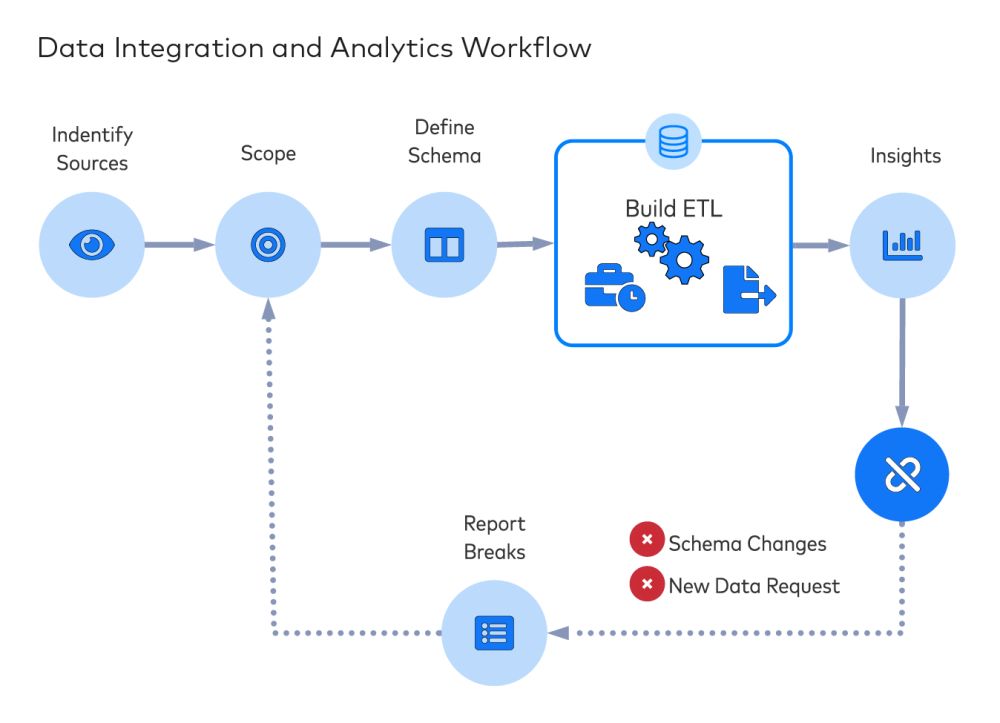
Außerdem überschreitet das Erstellen einer Data Pipeline häufig die technischen Fähigkeiten (oder die Bedürfnisse) der Analysten. In der Regel sind dafür die enge Zusammenarbeit mit Mitarbeitern des IT- und Data Engineering-Teams sowie das Schreiben von Code erforderlich, um die einzelnen Datenquellen zu extrahieren und zu transformieren. Ebenso wie undichte Rohrleitungen – Rohrleitungen, durch die das Geld von Unternehmen fließt – erfordern Data Pipelines Instandhaltung und Aufmerksamkeit im Hintergrund. Ganz zu schweigen von der Komplexität der Erstellung einer idempotenten Data Pipeline.
Bei dem rapiden Wachstum cloudbasierter Optionen und den schnell sinkenden Kosten cloudbasierten Computings und cloudbasierter Datenspeicherung gibt es kaum einen Grund, weiter mit diesem Verfahren zu arbeiten. Heute können riesige Datenmengen mit geringem Kostenaufwand in der Cloud gespeichert und die Data Analytics-Abläufe mit einem SaaS-Data Pipeline-Tool verbessert und vereinfacht werden.
Zusammengefasst ausgedrückt können Sie die Daten jetzt (über die Cloud) extrahieren und laden und sie dann zu Analysezwecken nach Bedarf transformieren. Wenn Sie eine Entscheidung zwischen ETL und ELT treffen müssen, sollten Sie sich definitiv für ELT entscheiden.
Automatisierte Data Connectors
Ihre Datentechniker können ohne Schwierigkeiten Konnektoren erstellen, um Daten aus einer Vielzahl von Plattformen zu extrahieren. Vor dem Erstellen von Data Connectors sollten Sie unsere Erwägungen zum Thema Erstellen im Vergleich zum Kauf von Data Pipelines lesen. Die Kosten variieren je nach Region und Gehaltsstufen, aber Sie können einige schnelle Berechnungen durchführen und dann entscheiden, ob sich der Aufwand und das Risiko lohnen.
Datentechniker würden sich lieber auf wichtigere Projekt konzentrieren, als Daten von Punkt A an Punkt B zu übertragen, von der Instandhaltung der bereits erwähnten „undichten Rohrleitungen“ mal ganz abgesehen.
Wägen Sie den Aufwand der manuellen Erstellung von Konnektoren gegen ein automatisiertes Data Pipeline-Tool ab. Diese Art von Tool überwacht Datenquellen auf Änderungen jeglicher Art und kann den Vorgang der Datenintegration automatisch ohne Unterstützung durch Entwickler anpassen.
Somit sind automatisierte Data Connectors der effektivste Weg, die Programmierer zu entlasten und Datenanalytikern und Datenwissenschaftlern mehr Möglichkeiten zu bieten.
Und wenn der Datentransfer (oder das Data Pipelining) geregelt sind, können sich Datentechniker einer wertvolleren und interessanteren Aufgabe widmen: der Katalogisierung von Daten für interne Interessenvertreter und der Vermittlung zwischen Analyse und Datenwissenschaft.
Warum Fivetran?
Die automatisierten Data Connectors von Fivetran sind vorgefertigt und vorkonfiguriert und unterstützen mehr als 150 Datenquellen, einschließlich Datenbanken, Cloud-Diensten und Cloud-Anwendungen. Die Fivetran-Konnektoren passen sich automatisch an, wenn Anbieter Änderungen an ihren Schemata vornehmen können, indem sie Spalten hinzufügen oder entfernen, den Typen eines Datenelements ändern oder neue Tabellen hinzufügen. Außerdem verwalten unsere Pipelines die Normalisierung der Daten und schaffen abfragebereite Daten-Assets für Ihr Unternehmen, die fehlertolerant sind und im Falle eines Systemausfalls die automatische Wiederherstellung ermöglichen. Erfahren Sie mehr über unsere Lösungen für die automatisierte Datenintegration.
Free eBook: Build vs Buy Data Pipeline Guide
DOWNLOADStart your 14-day free trial with Fivetran today!
Get started today to see how Fivetran fits into your stackShare
Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.
Vielen Dank! Ihre Einreichung wurde empfangen!
Hoppla! Beim Absenden des Formulars ist ein Fehler aufgetreten.









