Was ist ein Data Lakehouse?


Ein Data Lakehouse, ein kontrollierter Data Lake, ist eine Datenplattform, welche die Wirtschaftlichkeit und Flexibilität eines Data Lake mit den Governance- und Abfragemöglichkeiten eines Data Warehouse vereint. Dank der Nutzung von offenen Tabellenformaten und Datenkatalogen replizieren Data Lakehouses die SQL-basierten Funktionen von Data Warehouses und sorgen gleichzeitig für Übersicht und Kontrolle in Bezug auf die im Data Lake gespeicherten Tabellendaten.
Ein Data Lakehouse ist ein leistungsfähiges zentrales Repository für Daten, das alle Arten analytischer und betrieblicher Anwendungsfälle von Daten unterstützt, von Berichtsfunktionen, Business Intelligence und Streaming bis hin zu maschinellem Lernen und künstlicher Intelligenz.
Data-Lakehouse-Architektur
Die Architektur eines Data Lakehouse besteht aus fünf entscheidenden Schichten.
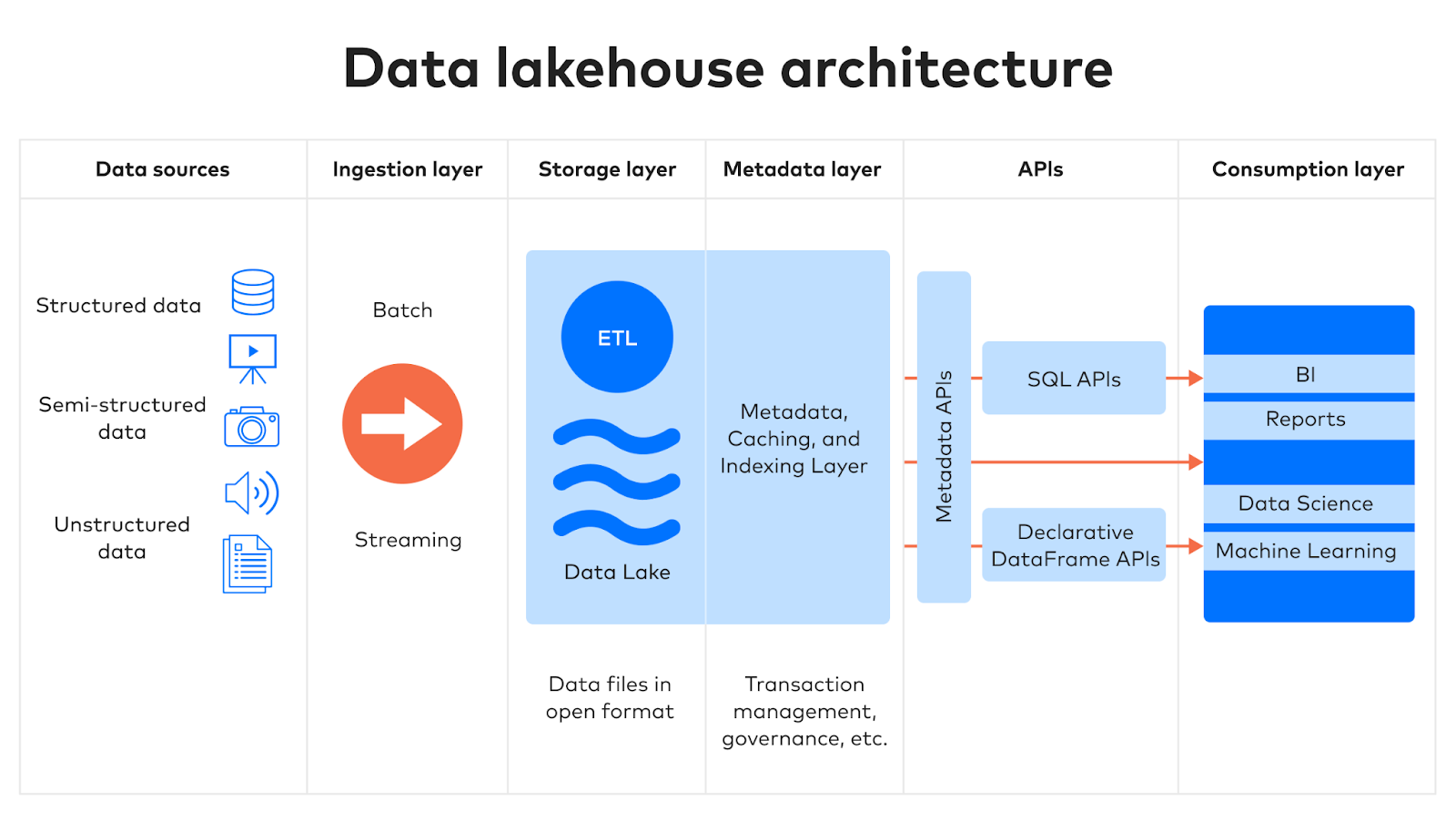
1. Eingabe
In der ersten Schicht werden Daten aus mehreren Quellen erfasst und an die Speicherschicht gesendet. Diese Daten stammen entweder aus internen oder externen Quellen, beispielsweise:
- Datenbanken, einschließlich relationaler Datenbankmanagementsysteme (RDBMS) und halbstrukturierter NoSQL-Datenbanken
- ERP (Enterprise Resource Planning), CRM (Customer Relationship Management) und weitere SaaS-Anwendungen (Software-as-a-Service)
- Ereignisströme
- Dateien
Der Fivetran Managed Data Lake Service wurde dafür entwickelt, diesen Schritt zu vereinfachen. Zusätzlich zur Verschiebung von Daten aus einer Quelle zu einer Destination normalisiert, komprimiert und dedupliziert die Fivetran-Pipeline die Daten und konvertiert sie in ein offenes Tabellenformat.
2. Speicherung
Data Lakehouses verwenden offene Tabellenformate für die Speicherung strukturierter und halbstrukturierter Daten und nutzen Rohdateien für unstrukturierte Daten. Genau wie herkömmliche Data Lakes bieten Data Lakehouses Skalierbarkeit und Flexibilität und entkoppeln Speicherung und Computing, was ein hohes Maß an Modularität ermöglicht.
Lakehouses verwahren Schemata strukturierter und halbstrukturierter Datensätze in der Metadatenschicht, sodass Datenteams den Inhalt des Lakehouse überwachen und kontrollieren können, was die Governance erleichtert.
3. Metadaten
Metadaten sind Daten mit Informationen über andere Datenelemente. Die Metadatenschicht eines Data Lakehouse ist ihr großer Vorteil gegenüber nicht kontrollierten Data Lakes.
Die Metadatenschicht enthält einen Katalog, der Metadaten zu allen Objekten im Speicher des Data Lake bietet. Sie ermöglicht Benutzern zudem die Implementierung von Funktionen wie ACID-Transaktionen, Indexierung, Zwischenspeicherung und Datenversionierung.
Die Metadatenschicht ermöglicht es Benutzern zudem, Architekturen von Data-Warehouse-Schemata umzusetzen, beispielsweise Snowflake oder Star-Schemata, um die Schemaverwaltung zu verbessern. Audit-Verfahren und Data Governance können direkt im Data Lake erfolgen, was die Datenintegrität und das Vertrauen in die Daten und daraus abgeleitete Produkte stärkt.
4. APIs
SQL- und DataFrame-APIs ermöglichen Analysten, Datenwissenschaftlern und anderen Benutzern den Zugriff auf und die Abfrage von Daten über ihre bevorzugten Sprachen. Datenexperten bevorzugen für einfachere Transformationen und Berichterstattung üblicherweise SQL und nutzen Python, R, Scala und andere Sprachen für komplexere Datenvorgänge.
5. Verbrauch
Business-Intelligence-Plattformen und Data-Science-Anwendungen jeder Art befinden sich in der Verbrauchsschicht und beziehen über die API analysebereite Daten aus dem Lake, um Berichte, Dashboards und Datenprodukte aller Art zu erstellen, einschließlich maschinellem Lernen und künstlicher Intelligenz.
Wichtige Merkmale und Vorteile eines Data Lakehouse
Ein Data Lakehouse kombiniert die Funktionen von Data Lakes und Data Warehouses, einschließlich der folgenden Schlüsselfunktionen:
- Unterstützung für ACID-Transaktionen: Data Lakehouses ermöglichen ACID-Transaktionen, die normalerweise Data Warehouses vorbehalten sind, und sorgen so für Einheitlichkeit, wenn mehrere Parteien gleichzeitig Daten lesen und schreiben.
- BI-Unterstützung: Dank Unterstützung für ACID und SQL-Abfrage-Engines können Analysten Business-Intelligence-Plattformen direkt mit Data Lakehouses verbinden.
- Offene Speicherformate: Data Lakehouses verwenden offene Speicherformate, die von einem Datenteam mit einer bevorzugten Compute-Engine kombiniert werden können. Sie sind nicht an die monolithische Datenanalysearchitektur eines Anbieters gebunden.
- Schema- und Governance-Funktionen: Data Lakehouses unterstützen Schema-On-Read, wobei die Software während des Zugriffs auf die Daten ihre Struktur bestimmt. Ein Data Lakehouse unterstützt Schemata für strukturierte Daten und sorgt für die Schemadurchsetzung und somit dafür, dass die in die Tabelle hochgeladenden Daten dem Schema entsprechen.
- Unterstützung für vielfältige Datentypen und Workloads: Data Lakehouses können sowohl strukturierte als auch unstrukturierte Daten enthalten, dienen also neben der Verarbeitung relationaler Daten auch der Speicherung, Transformation und Analyse von Bildern, Video- und Audioaufnahmen, Texten sowie halbstrukturierten Daten wie JSON-Dateien.
- Entkoppelung von Speicher und Computing: Speicherressourcen sind unabhängig von Compute-Ressourcen. Die daraus gewonnene Modularität ermöglicht es, Kosten und Skalierung der jeweiligen Bestandteile separat und den Anforderungen Ihrer Workloads entsprechend zu steuern, sei es für maschinelles Lernen, Business Intelligence und Analysen oder Data Science.
Diese Funktionen bieten Datenteams die folgenden Vorteile:
- Skalierbarkeit: Kommerzielle Cloud-Speicher sind die Grundlage von Data Lakehouses, was sie sehr skalierbar macht.
- Verbesserte Datenverwaltung: Die Speicherung vielfältiger Daten ermöglicht es Data Lakehouses, alle Anwendungsfälle von Daten zu unterstützen, von der Berichterstattung bis hin zu Prognosemodellen oder generativer KI.
- Optimierte Datenarchitektur: Data Lakehouses vereinfachen die Datenarchitektur, da keine Data Lakes als Bereitstellungsbereich für Data Warehouses mehr erforderlich sind. Ebenso ist es nicht mehr erforderlich, ein separates Data Warehouse für Analysen und einen Data Lake für Streamingprozesse zu unterhalten.
- Geringere Kosten: Die optimierte Architektur senkt zudem die Kosten.
- Vermeidung von Datenredundanz: Da Daten in einem Lakehouse vereinheitlicht werden, sind keine redundanten Kopien von Daten mehr erforderlich. Dies senkt die Speicheranforderungen und vereinfacht die Governance.
Data Lakehouses blicken einer strahlenden Zukunft entgegen
Das Data Lakehouse wurde erstmals 2017 von Databricks vorgestellt und entwickelte sich zu einem quelloffenen Projekt, das Data Lakes zuverlässiger machen sollte. Seitdem begannen alle großen Anbieter von Cloud-Plattformen, die gleiche Architektur anzubieten.
Data Lakehouses eignen sich optimal für die folgenden Anwendungsfälle:
- Maßstab, Umfang und Komplexität des Datenbedarfs von Unternehmen werden weiter zunehmen. Dadurch werden die Kostenvorteile und Flexibilität von Data Lakes noch bedeutsamer.
- Unternehmen streben danach, ihre Datenarchitektur zu vereinfachen und Redundanzen zu vermeiden, um Kosten zu senken und die Governance zu verbessern.
- Angesichts innovativer Anwendungsfälle wie generativer KI ist es noch wichtiger geworden, alle Daten eines Unternehmens an einem Ort zu haben.
Mit dem Fivetran Managed Data Lake Service sind Datenintegration und Data Movement im Data Lakehouse einfach und zuverlässig. Melden Sie sich noch heute für eine kostenlose Trial an.
Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.









