Qu’est-ce qu’un data lakehouse ?


Un data lakehouse, ou data lake bénéficiant d’une gouvernance, est une plateforme de données qui combine la rentabilité et la flexibilité d'un data lake avec les capacités de gouvernance et d'interrogation d'un data warehouse. Grâce à l'utilisation de formats de table ouverts et de catalogues de données, les data lakehouse reproduisent la fonctionnalité SQL des data warehouses, tout en garantissant la visibilité et le contrôle des données tabulaires stockées dans le data lake.
Le data lakehouse est un puissant référentiel central de données qui prend en charge toutes sortes d'utilisations analytiques et opérationnelles des données, allant du reporting, de l’informatique décisionnelle et du streaming à l'apprentissage automatique et l’intelligence artificielle.
Architecture d’un data lakehouse
L'architecture d'un data lakehouse se compose de cinq couches principales.
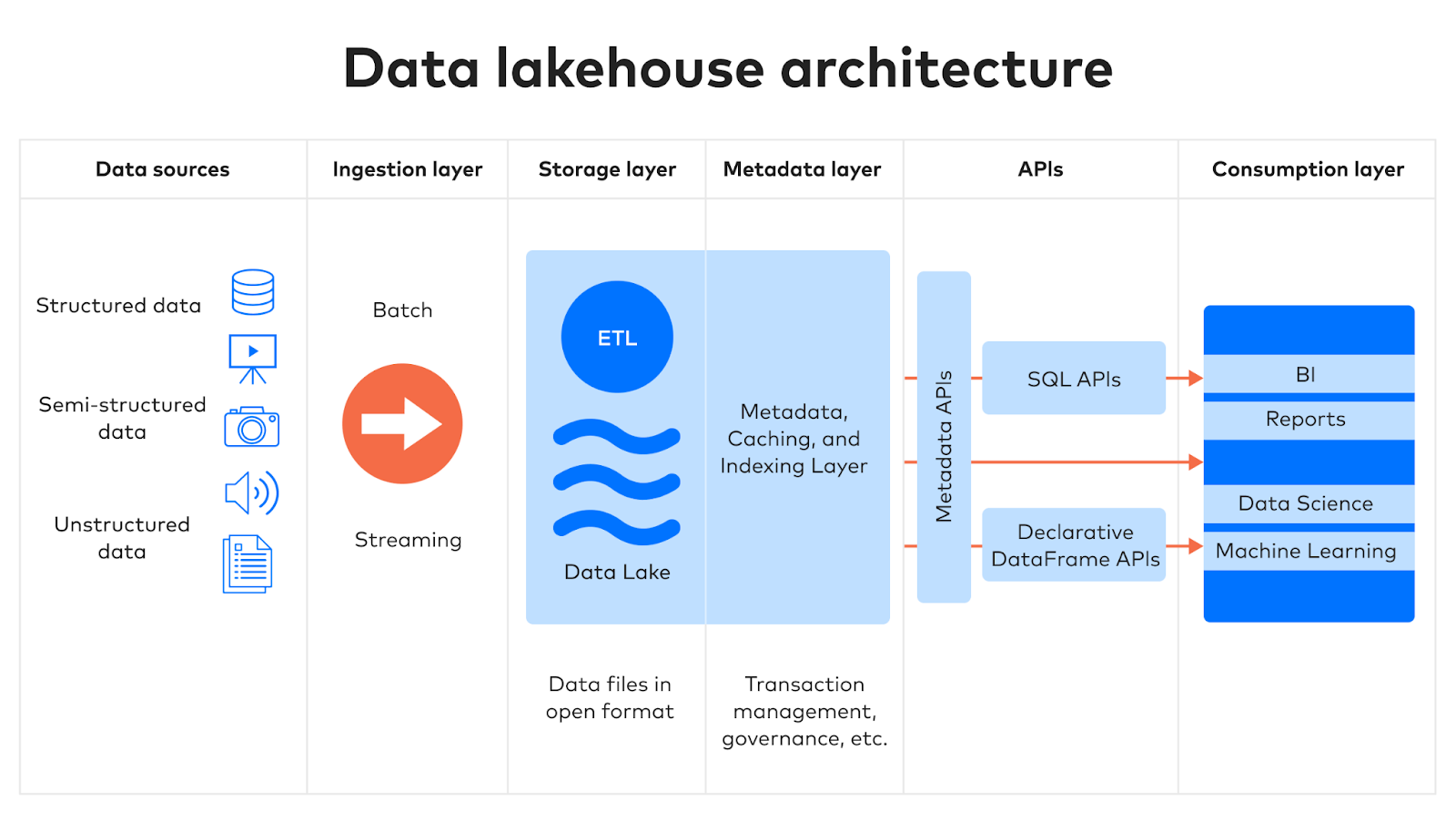
1. Ingestion
Dans la première couche, les données provenant de sources multiples sont collectées et transmises à la couche de stockage. Ces données peuvent provenir de sources internes ou externes, telles que :
- Des bases de données, y compris les systèmes de gestion de bases de données relationnelles (SGBDR) et les bases de données semi-structurées NoSQL
- La planification des ressources de l'entreprise (ERP), la gestion des relations avec la clientèle (CRM) et d'autres applications SaaS (Software-as-a-Service)
- Des flux d’événements
- Des fichiers
Le service Managed Data Lake de Fivetran (gestion de data lake) est conçu pour faciliter cette étape. En plus de déplacer les données de la source à la destination, le pipeline Fivetran normalise, compacte et déduplique les données tout en les convertissant dans un format de table ouvert.
2. Stockage
Les data lakehouses utilisent des formats de table ouverts pour stocker les données structurées et semi-structurées, ainsi que des fichiers bruts pour les données non structurées. Comme les data lakes classiques, les data lakehouses offrent évolutivité et flexibilité, en dissociant les ressources de stockage des ressources de calcul et en permettant un haut degré de modularité.
Les lakehouses conservent les schémas des ensembles de données structurées et semi-structurées dans la couche de métadonnées, ce qui permet aux équipes chargées des données d'observer et de contrôler le contenu du lakehouse, facilitant ainsi la gouvernance.
3. Métadonnées
Les métadonnées sont des données qui contiennent des informations sur d'autres éléments de données. La couche de métadonnées d'un data lakehouse est son principal avantage par rapport aux data lakes sans capacité de gouvernance.
La couche de métadonnées héberge un catalogue qui fournit des métadonnées pour chaque objet contenu dans le stockage du lake. Elle permet également aux utilisateurs d’implémenter des fonctionnalités telles que les transactions ACID, l'indexation, la mise en cache et la gestion des versions des données.
La couche de métadonnées permet également aux utilisateurs de mettre en œuvre des architectures de schémas de data warehouse, comme les schémas en flocon de neige ou en étoile, et d'améliorer la gestion des schémas. L'audit et la gouvernance des données peuvent être effectués directement dans le data lake, ce qui améliore l'intégrité des données et renforce la confiance dans les données et leurs produits dérivés.
4. API
Les API SQL et DataFrame permettent aux analystes, aux data scientists et aux autres utilisateurs d'accéder aux données et de les interroger en utilisant leurs langages préférés. Les professionnels des données sont susceptibles de préférer SQL pour les transformations et les rapports simples, et d'utiliser Python, R, Scala ou d'autres langages pour des manipulations de données plus complexes.
5. Consommation
Les plateformes d’informatique décisionnelle et les applications de science des données de tous types se situent dans la couche de consommation, puisant dans le data lake des données transformées et prêtes pour l'analyse via l'API, afin de produire des rapports, des tableaux de bord et des produits de données de toutes sortes, tels que l'apprentissage automatique et l'intelligence artificielle.
Fonctionnalités clés et avantages d'un data lakehouse
Un data lakehouse combine les capacités des data lakes et des data warehouses, y compris les fonctions clés suivantes :
- Prise en charge des transactions ACID : Les data lakehouses permettent les transactions ACID, normalement associées aux data warehouses, afin de garantir la cohérence lorsque plusieurs parties lisent et écrivent simultanément des données.
- Prise en charge BI : Grâce à la prise en charge ACID et aux moteurs de requête SQL, les analystes peuvent connecter directement les data lakehouses aux plateformes d’informatique décisionnelle.
- Formats de stockage ouverts : Les data lakehouses utilisent des formats de stockage ouverts, que l'équipe chargée des données peut combiner avec le moteur de calcul de son choix. Vous n'êtes pas enfermé dans l'architecture d'analyse de données monolithique d'un seul fournisseur.
- Capacités en matière de schéma et de gouvernance : Les data lakehouses prennent en charge le «schema-on-read» (schéma en lecture), c'est-à-dire que le logiciel qui accède aux données détermine leur structure sur-le-champ. Un data lakehouse prend en charge les schémas pour les données structurées et assure l'application des schémas pour garantir que les données téléchargées dans une table correspondent au schéma.
- Prise en charge de divers types de données et de charges de travail : Les data lakehouses peuvent contenir à la fois des données structurées et non structurées. Outre le traitement des données relationnelles, vous pouvez donc les utiliser pour stocker, transformer et analyser des images, des vidéos, du son et du texte, ainsi que des données semi-structurées comme les fichiers JSON.
- Stockage et calcul dissociés : Les ressources de stockage sont dissociés des ressources de calcul. Vous disposez ainsi de la modularité nécessaire pour maîtriser les coûts et faire évoluer les unes ou les autres séparément pour répondre aux besoins de vos charges de travail, qu'il s'agisse d'apprentissage automatique, d’informatique décisionnelle et d'analyse, ou de science des données.
Ces fonctions offrent aux équipes chargées des données les avantages suivants :
- Évolutivité : Les data lakehouses s'appuient sur le stockage cloud de produits de base, ce qui signifie qu'ils sont très évolutifs.
- Amélioration de la gestion des données : En stockant des données diverses, les data lakehouses peuvent prendre en charge tous les cas d'utilisation des données, du reporting à la modélisation prédictive en passant par l'IA générative.
- Simplification de l’architecture de données : Le data lakehouse simplifie l'architecture des données en éliminant la nécessité d'utiliser un data lake comme zone de transit pour un data warehouse, ainsi que la nécessité de maintenir un data warehouse séparé pour l'analyse et un data lake pour les opérations de streaming.
- Réduction des coûts : L'architecture simplifiée permet également de réduire les coûts.
- Élimination des données redondantes : Comme les données sont unifiées dans un lakehouse, il n'est plus nécessaire d'avoir des copies redondantes des données. Cela réduit les besoins de stockage et facilite la gouvernance.
Les data lakehouses ont un avenir radieux
Le data lakehouse a été lancé pour la première fois par Databricks en 2017, devenant par la suite un projet open-source visant à renforcer la fiabilité des data lakes. Depuis, d'autres grands fournisseurs de plateformes cloud ont commencé à proposer la même architecture.
Les data lakehouses sont la solution idéale pour les cas d'utilisation suivants :
- Les besoins en données d'une organisation devraient continuer à augmenter en termes d'échelle, de volume et de complexité, ce qui rend plus significatifs les avantages en termes de coûts et de flexibilité offerts par l'utilisation d'un data lake pour le stockage.
- Une organisation souhaite simplifier son architecture de données et éliminer les redondances afin de maîtriser les coûts et d'améliorer la gouvernance.
- Des cas d'utilisation innovants, tels que ceux impliquant l'IA générative, font qu'il est de plus en plus utile d'avoir toutes les données d'une organisation en un seul endroit.
Le service Managed Data Lake de Fivetran rend l'intégration et le transfert des données dans le data lakehouse simple et fiable. Inscrivez-vous dès aujourd'hui pour un essai gratuit.
Articles associés
Commencer gratuitement
Rejoignez les milliers d’entreprises qui utilisent Fivetran pour centraliser et transformer leur data.









