What is a database schema: Types, benefits & key style examples

Database schemas help with data integration and optimization to drive better analysis and results.
In 2022, the total amount of data created, captured, copied and consumed globally is estimated to reach 97 zettabytes. By 2025, researchers forecast it will exceed 181 zettabytes.
To put things into perspective, each zettabyte is the information equivalent to about a trillion truckloads of paper.
Modern-day businesses collect a massive amount of data from both internal and external sources. They need a way to structure, store and access this data. This is where a database schema comes in.
A database schema is a blueprint that describes how data is organized and the relationships between the different elements within a database. These schemas enable analysts to import data from third-party sources, reconcile the data with their own systems and answer their questions.
In this article, we’ll delve into database schemas — what they are, why businesses need them, the different types of schemas and how you can build your own.
[CTA_MODULE]
What is a database schema?
A database schema outlines how key elements in a relational database, such as tables and records, are organized and connected with each other.

The schema is often visually represented using an entity-relationship diagram that outlines which values your database will store and how, the relationships between them and the rules that will govern them.
It ensures:
- Consistent data formatting
- Unique primary keys for every record entry
- Inclusion of all essential data
- A foreign key to define the relationships between different entities
The main aim of a schema is to build a framework that serves the end user, whether it’s an engineer, analyst or administrator. For example, an effective schema can streamline reporting processes for analysts.
The process of building a database schema is called database modeling. The schema helps programmers accurately understand the size and complexity of a project before creating a database and its relationships.
Typically, schemas are used for constructing database management systems (DBMSs) and relational database management systems (RDBMSs).
Schemas can satisfy several considerations, including:
- Redundancy
- Operational efficiency
- Interpretability
- Performance
- Cost savings
- Specific analytics or machine learning applications
Good database schema design can mean the difference between a query taking seconds or hours to be processed.
A schema can also be in the form of a set of formulas or use constraints that developers can implement using different languages, such as MySQL or Oracle Database.
Database schema vs. database instance
A database schema is a framework or outline used to plan a database. It does not contain any actual data values.
A database instance is a snapshot of the entire database system and all its elements at a single moment in time.
These elements affect each other in a DBMS, where the schema imposes constraints that every instance must comply with. The schema typically remains static once the database is operational, but instances change.
Types of database schemas
There are three main types of database schemas:
- Conceptual database schema: This is a high-level overview of what your database will contain, how the data will be organized and the rules the data will follow. This type of schema is created in the initial project stage.
A conceptual schema focuses on the main concepts and their relationships. It doesn’t dig into any of the details and is thus insufficient to build a database.
- Logical database schema: This schema clearly defines all the elements within the database and any related information, such as field names, entity relationships, integrity constraints and table names.
A logical database schema states the logical rules or constraints that dictate how the elements within a database interact. The creation process for it varies depending on the project’s requirements.
- Physical database schema: A physical schema combines contextual and logical information while adding technical requirements. It contains the syntax needed to create data structures within the disk storage.
Both logical and physical schemas include a primary key that serves as a unique identifier for every entry in the table.
Benefits of database schemas
There are three vital benefits to using a database schema.
- Ensures data integrity
A well-designed schema helps ensure data integrity. You can use a database schema to design a new database, import data from a different source into your application or a data warehouse or optimize an existing database.
In all of these scenarios, database schemas can ensure consistent formatting and the maintenance of unique primary and foreign keys.
- Better accessibility
In the data analytics world, both data sources and data warehouses use schemas to define data elements.
But the schemas for data sources — whether they’re databases such as MySQL, PostgreSQL or SQL Server, or SaaS applications such as Salesforce or Zuora — are often designed with operations rather than analytics in mind.
And while data sources such as SaaS apps may provide some general analytics functionality, they cover only the data from that single application.
To make the best of your analytics, you will need schemas designed for analytics purposes and the ability to connect data between sources.
This will provide you with primary and foreign keys to identify the same entities across multiple data sources, enabling you to join data from various sources and analyze the combined data for better insights.
- Improved reporting
A well-designed schema ensures that analysts don’t have to:
- Clean data or preprocess it before analyzing it
- Reverse-engineer the underlying data model
- Search for a starting point for analytics
A schema designed for analytics means faster access to data for creating reports and dashboards. The opposite means extra data modeling, the slow retrieval of data and the consumption of more resources (such as time and processing power) when creating reports for analysis.
Database schema integration requirements
Integrating data from multiple sources is beneficial for analysts. However, to seamlessly facilitate this integration, the following factors must be considered:
- Overlap preservation: When integrating data from multiple schemas, every overlapping element from each of them must be in a database schema table.
- Extended overlap preservation: Some elements appear in only one source but are related to the overlapping elements from other schemas. These should also be replicated in the final database schema.
- Normalization: Independent elements and relationships from different schemas should not be grouped into one table.
- Minimality: No entity from any of the integrated schemas should be lost.
How to design a schema for data integration
You need a schema for every data source you import into your data warehouse. The data provider may have organized their data model according to their assumptions about the metrics their users want, which may differ from your requirements.
Follow these steps to design a schema for data integration:
1. Understand the source’s data model
You need to understand the source’s data model to make sense of the data it will send your way.
To do that, you can talk to the developers and data engineers who work with the source database and ask them to explain the data model. This will work when you are trying to integrate data from a system within your organization or working with a partner willing to meet with you and discuss the data model.
If you have to integrate data from a SaaS provider, you can get documentation from the vendor that explains the data model. A better option is to integrate through a third party and use their data model; for example, here’s the Fivetran documentation for Salesforce.
When trying to understand the data model of an app, where meeting with developers or acquiring documentation is not an option, you can talk to the users of the application and see how the data flows.
Based on what you find, you can start creating entity-relationship diagrams (ERDs) and make sense of how the data flows in the app.
2. Create entity-relationship diagrams (ERD)
Entity-relationship diagrams (ERDs) are visual representations of schemas or entity-relationship models. You can use these to better understand how different tables relate to each other and get buy-in from analysts and end users.
There are three types of relationships between entities in different tables:
One-to-one: Two entities can only map onto each other and no other elements.

Think of Social Security numbers — they are unique to each person and will only have a one-to-one relationship with each person. In Fivetran ERDs, if we encounter a nested object that has a one-to-one relationship with the main table, we simply flatten its data into columns.
One-to-many: One entity in a table can relate to many entities in a different table, but the opposite is not true.

Think of ice cream flavors sold by a company and the customers who have ordered products that feature them. A food retailer might use that data to determine a customer’s favorite flavor.
That business insight can then be used to proactively recommend new ice creams that feature that flavor as they come to market.
The business value of the one-to-many database is therefore demonstrated: finding insights around commonalities in user behavior and the data it generates and aligning them with actions that drive revenue.
Each flavor can have many customers, but each customer only has a single favorite, which rises above all others. If we encounter a nested object with a one-to-many relationship to the main table, it is turned into a separate table.
Many-to-many: One entity in a table can relate to many entities in a different table and the opposite is also true. A many-to-many relationship between entities results in a new table called the join table that has primary keys from both tables.

For instance, a person’s shopping habits might bring them to many stores and each store will have many customers. The join table in the above diagram shows both customer-id and shop-id, which are primary keys in their own tables and present a clear relationship between customers and shops in the join table.
3. Normalize the data
Data normalization helps eliminate data redundancy. When normalizing data, you define rules that divide larger tables into smaller tables, link them using relationships and ensure the data appears consistent across all fields and records.
There are six stages of data normalization:
- First Normal Form (1NF): You make sure there are no hidden values in any columns and only one value in each field.
- Second Normal Form (2NF): You make sure all non-key columns depend on the primary key.
- Third Normal Form (3NF): Non-primary key columns don’t depend on other non-primary key columns.
- Fourth Normal form (4NF): The table should not have any multi-valued dependency.
- Fifth Normal form (5NF): The table can be decomposed and recomposed again without losing or gaining any data.
- Sixth Normal form (6NF): The relation variables are decomposed into irreducible components and do not support nontrivial dependencies.
6NF is the final level of normalization. You can stop at any stage of data normalization, depending on the use case and your requirements.
After normalization, you can:
- Preprocess the data into a normalized schema and load it into its destination
- Publish your finalized ERD for your analysts
Dimensional schemas
A dimensional schema is a database schema that consolidates information from numerous data sources. It is used to create a definitive but streamlined source of truth that is comprehensive enough to answer a wide range of business questions.
Before creating a dimensional schema, developers need a conceptual model that standardizes the relationship between different data elements such as name, email address, last purchase, etc.
Developers collect information from stakeholders about how they handle data at the organization before creating a conceptual data model.
Developers also need a set of rules, called an internal system of record, that resolves conflicts between data sources.
This internal system of record helps developers determine which data to capture from which sources and how it is produced and handled by different teams in an organization.
Think of data that’s shared between the marketing team and the sales team at a company. For example, marketing runs multiple campaigns and asks people to sign up for product demos. Then, people who sign up for the demos are passed onto sales as marketing qualified leads (MQLs).
The data model that represents these operations should cover:
- The information that needs to be captured: Name, email address, phone number, job title, company name, product, date, time, campaign name
- The place the information will be stored: A separate table for each prospect using the email ID as the key identifier
- The way the information will travel: From the lead capture form to the central database, from the database to Salesforce (or a similar system)
The data model is tested thoroughly by asking it questions that it can’t answer to build resiliency. For example, what if the prospect changes their mind and does not want to participate in the demo anymore? What if they sign up for a free trial or purchase the product before going through a demo?
In both these scenarios, there needs to be an additional piece of information - a “maybe” status that captures whether the prospect has to go through the demo, has gone through the demo, canceled the demo and more.
Once the data model is finalized and the developer has a better understanding of the information related to different business processes at an organization, they can move toward building the dimensional schema.
Styles of database schemas
There are six types of database schemas based on end-user interactions with database systems.
1. Star schema
Star schemas make it easy to query large amounts of data, aggregate it into smaller chunks and use it for business intelligence and analytics.
They are ideal if you are working with a large collection of raw data and want to organize it, or are reconstructing a large data mart or data warehouse.
The star schema has a fact table at its center and multiple dimensional tables that connect to it.

The fact table contains all of the metrics of a business process and usually has numerical values. The dimension table contains data elements that are related to dimensions such as location, time, product and people.
For example, the dimension tables for the example we discussed in the previous section, i.e., a prospect signing up for a demo, will contain information about:
- The lead forms used by marketing to generate MQLs
- The campaigns run by marketing
- The date and time of the campaigns
- The contact information of users signing up for demos
The fact table will contain information from the dimension tables for each MQL. The dimension table regarding products will provide the product ID, the contact information table will provide the email ID and so on.
Each of these IDs serves as key identifiers or primary keys in dimension tables but will serve as foreign keys for the fact table.
To avoid redundancies, there can be only one table for each dimension, so all the information about products and their IDs will live in the “product” dimension table and nowhere else.
The data in the fact table depends on data from the dimension tables for it to make sense, i.e., you can have the prospect’s contact information live in the fact table, but the dimension tables tell you the activity they performed, the product they are interested in and more.
2. Snowflake schema
Snowflake schema helps save disk space because the data is highly structured. Snowflake schema is used for highly complex queries and advanced analytics.
Just like star schema, snowflake schema also has a fact table at its center and multiple dimension tables that connect to it. The only difference between the two is that the dimension tables in a snowflake schema are further joined to normalized tables.

So a dimension table for “date” can be further normalized into tables for day, week, quarter and so on. All of these new tables can connect to the parent dimension table.
The dimension table having further normalized tables allows for more complexity in how data is handled by the organization. For example, if a prospect expressed interest in one product but later expressed interest in more products via live chat or email conversations, the product “dimension” will benefit from a “child” dimension table.
3. Relational model
This type of schema is great for object-oriented programming, where data about objects takes precedence over logic and functions.
The relational model of database schema has a separate table for each object and each table can relate to multiple tables. An object, in this case, is a set of variables that defines the state of the object and the behavior of the object.

The above image shows the relational model of the database schema of a hospital. Each table relates to a specific object, i.e., prescription, procedure, room and appointment, are all objects that relate to each other in multiple ways.
Each table can relate to multiple tables and there is no central fact table as in star or snowflake schemas.
4. Network model
The network model is used in situations where one data item belongs in many categories. In the network model of a database, there’s a root table that connects to multiple child tables and each child table can connect to multiple other tables.

Each child table can have many parent tables, allowing for many interrelated pieces of data to be retrieved for analysis.
For example, if you are designing the database for a sports website, a network model will work well because every athlete will play for multiple teams and different teams will participate in different tournaments.
By having tables that relate to multiple tables, you’ll be able to store and retrieve data by athlete name, team name or tournament name. The downside to using this database schema is that you’ll need to store a column for player names separately in each table.
5. Hierarchical model
This type of schema is useful in environments where you need to be able to add and delete information quickly. It is generally used in the telecommunications, healthcare and banking industries. The data at the top of the hierarchy is quickly accessible.
In a hierarchical schema, there’s a root table (or segment) connected to multiple tables. Each table can have multiple child tables, but each child table can only have one parent table.
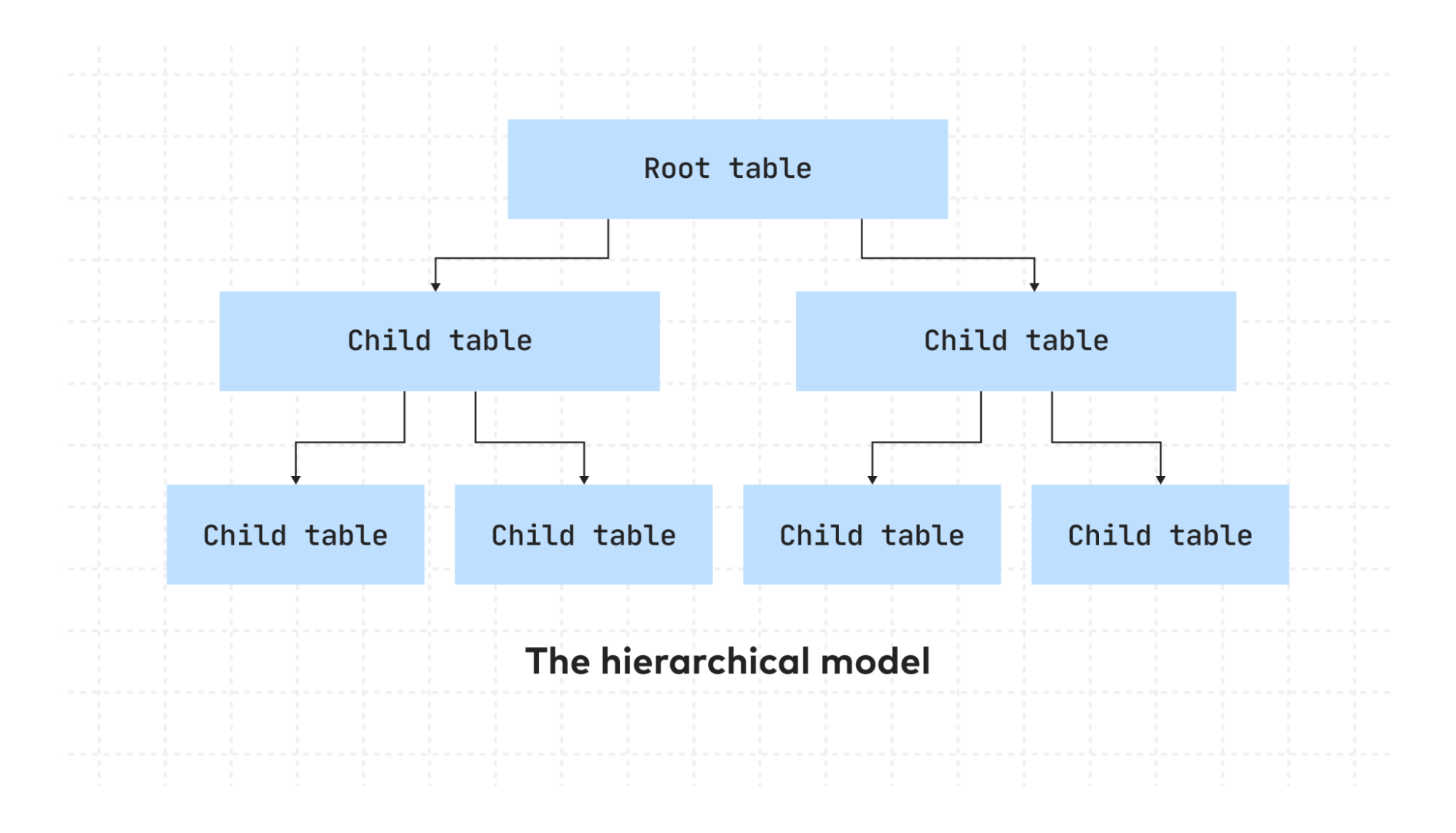
The only difference between this diagram and the network model above is that the child tables do not have multiple parent tables.
If we consider the banking sector, each bank maintains the records for multiple branches and accounts and each account has an account number, type, balance and customer information.
The account balance is more likely to keep changing regularly and the customer information, such as address and phone number, may change from time to time.
Keeping all of this information in a hierarchical structure allows the commonly used information to be retrieved quickly and easily.
6. Flat model
This type of schema is best for smaller, simpler databases. For example, a database management system that contains all of the daily transactions of a small-town bakery can function well on a flat model schema.
In a flat model database, there are multiple tables with multiple records, but the tables do not relate to each other, i.eThey exist in isolation.
It can also just be a single file containing only one table with rows of data separated by commas or tabs. Usually, email marketing tools use this type of database and the whole database or part of it can be downloaded as a CSV (comma-separated values) file.
Jumpstart your analytics with Fivetran
Database schema creation and implementation involve many complex steps. It can take your developers weeks or months to build a schema and then put it into action.
Instead, you can use Fivetran to get a fully managed, automated data pipeline. Every SaaS connector features normalized data schemas out of the box that also automatically adapt whenever the data source changes.
Once the data is warehoused, we make it quick and easy to transform data into analysis-ready models. You can experience Fivetran’s platform for yourself, completely free.
[CTA_MODULE]
After your free trial ends, continue on our Free Plan to use our no-maintenance pipelines for free, forever.
Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.









