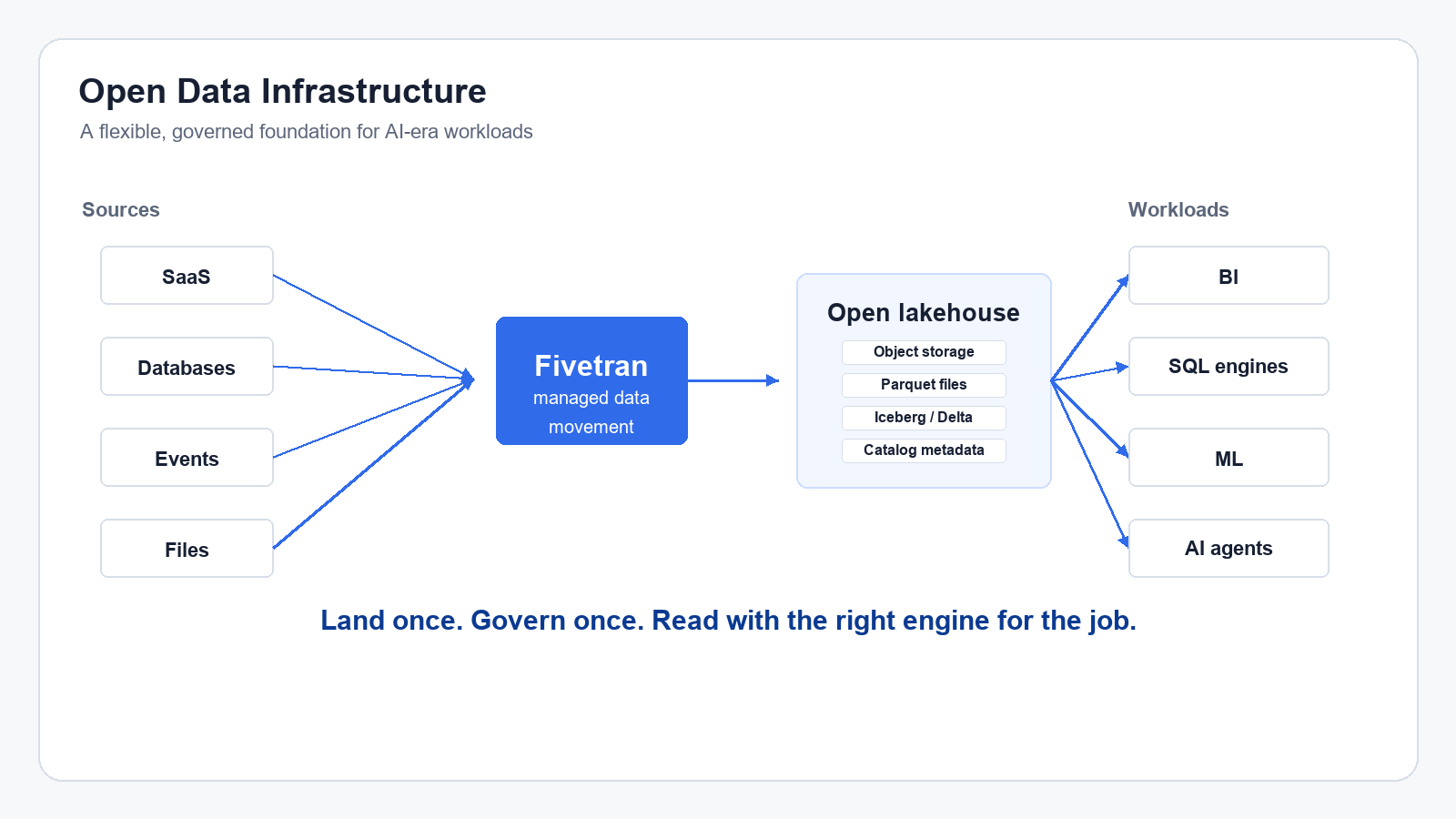
How to assemble your Open Data Infrastructure


Nobody knows what AI will need from your data stack next year, especially not Uncle Bob, who tried to sell you Bitcoin.
Models are converging. Agents are expanding. Tools are adapting. Last quarter's picture-perfect "AI stack" is described by AI gurus as antiquated and incomplete.
It is hard to know what to do to can get your data ready today for the AI of tomorrow.
In a constantly changing environment, you must design for motion. In game theory terms, you're operating under uncertainty. The rational move isn't to predict every future workload. The rational move is to preserve valuable options while protecting system integrity. Flexibility without integrity becomes chaos. Integrity without flexibility becomes lock-in. And unless you are the one holding the keys, you won't benefit from lock-in.

Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.









