How we transformed customer support with Fivetran-enabled AI


Every company that reaches a certain scale hits the same wall: the scale and complexity of its product grow faster than the support team's ability to hold it all in their heads.
Fivetran now supports over 750 data connectors — spanning SaaS applications, relational and NoSQL databases, event streams, file stores, ERPs like SAP, and fully custom sources built on our Connector SDK. Each connector has its own schema, change data capture method, failure mode, and troubleshooting path.
On top of that, support engineers need to be fluent in three distinct deployment architectures, multiple security and connectivity methods, and a full transformations layer that includes dbt Core and dbt Cloud integrations.
There is no single document (or brain) that contains all of that. And yet, every day, customers open tickets expecting fast, accurate answers.
This is the story of how we shifted from a purely human-operated, ticket-by-ticket model to an AI-augmented, efficiency-first support engine. By embedding our custom-built Fivetran Support AI app directly inside Zendesk, Fivetran now augments, summarizes, drafts, and quality-scores support interactions at scale.
[CTA_MODULE]
The real pain points
Before we built anything, we needed to identify where we could enhance our processes. Two things stood out above everything else:
- The first was handovers. Fivetran's support team operates around the clock across three global regions. That means daily follow-the-sun shift changes and coverage for time off. Every handover required manually written context notes. The quality of those notes was wildly inconsistent, and an incoming engineer picking up a complex, multi-week escalation might find themselves effectively starting from scratch. The team flagged this repeatedly in retrospectives. It wasn't a culture problem or a training problem, but a scaling problem: the manual process simply couldn't keep up with ticket volume and complexity.
- The second was acquisition complexity. Fivetran has acquired multiple products over time that have their own architectures, CDC methods, and documentation. Suddenly, support engineers have to be fluent in multiple systems. When a ticket for one of these acquired platforms landed with an engineer who wasn't fully onboarded, there was nowhere obvious to turn. The institutional knowledge lived with a small group of specialists who quickly became the default escalation point for questions that a proper knowledge system should have been able to answer.
Our vision was to resolve support tickets nearly instantly while minimizing human effort. The north star was an AI-first support system where humans act as architects, governors, and escalation experts, not ticket processors.
Building the solution on our own infrastructure
The Fivetran Support AI is a custom Zendesk plugin by our own engineering team that embeds AI directly into the ticket workflow. Rather than asking support engineers to leave Zendesk to consult documentation, we brought the knowledge to them.
But the plugin is only the interface. The real engine underneath is Fivetran's own data infrastructure. Data from every relevant source flows through our data lakehouse, gets transformed into AI-ready models using dbt, gets indexed into a search layer, and is served via an MCP server to OpenAI Agents. Those agents power the Zendesk widget that our engineers interact with in real time.
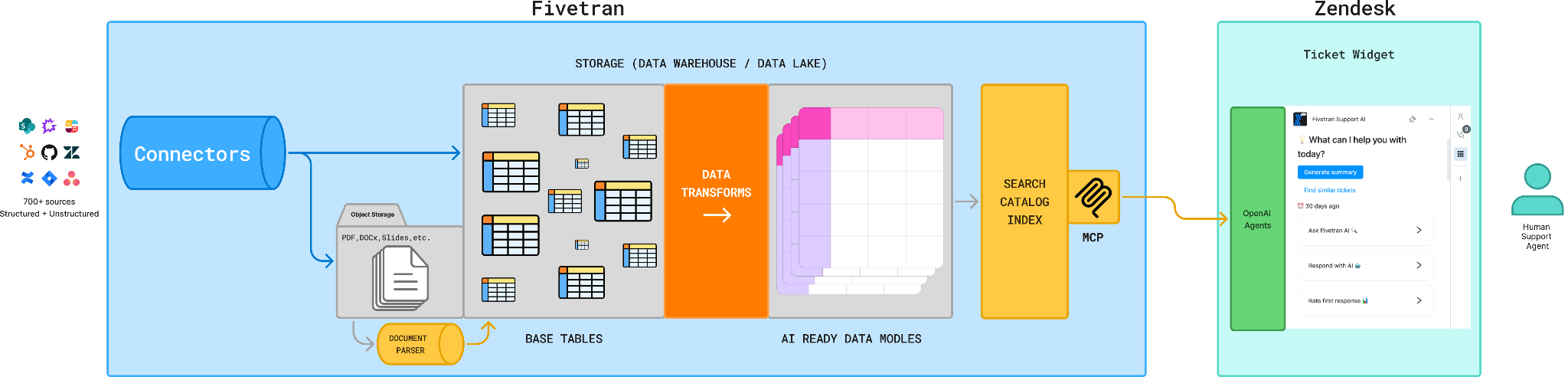
The knowledge base we built for this is comprehensive by design. It ingests full ticket history and comment threads from Zendesk, internal wiki content from Slab, engineering issues and pull requests from Jira and GitHub, product and technical documents from Google Drive, call recordings structured via Gong.io, account data from Salesforce, and our full public documentation scraped via our own Connector SDK.
We use the same connectors we sell to customers to centralize our own knowledge. Every piece of institutional knowledge that used to live in a Slack thread, a resolved ticket, or a specialist's memory is now queryable.
What Fivetran Support AI app actually does
The Fivetran Support AI app has four core capabilities that directly address the problems we identified.
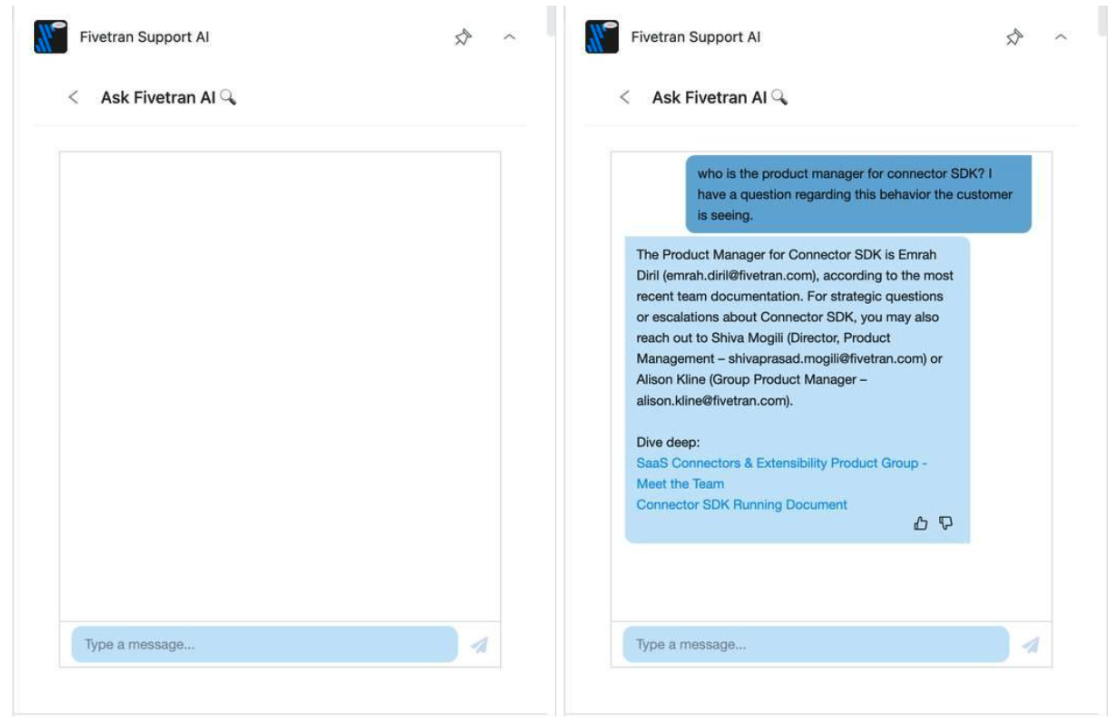
- Ask AI is a conversational interface embedded inside Zendesk. An engineer can ask any question — connector behavior, escalation paths, troubleshooting logic — and get a grounded, sourced answer without leaving their ticket. All conversations are retained within Zendesk for audit and continuous improvement.
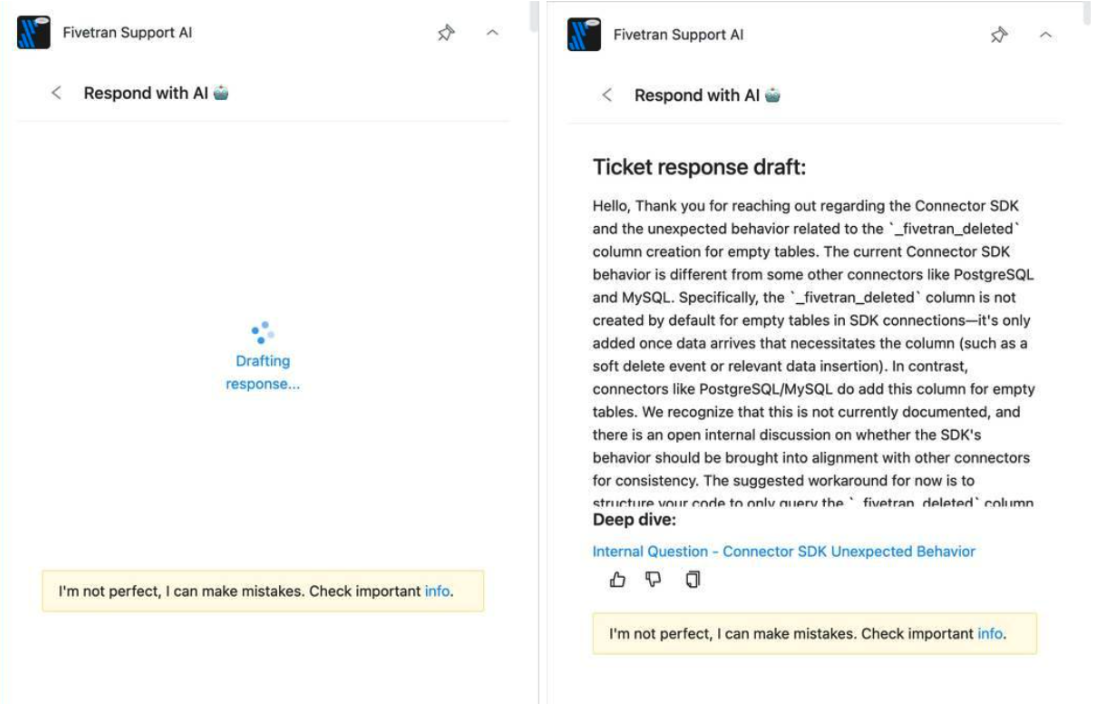
- Respond with AI generates a contextual draft response for every incoming ticket the moment it lands. The draft draws on prior ticket history, internal documentation, and resolved similar cases. Engineers review, personalize, and send. They never start from a blank page.
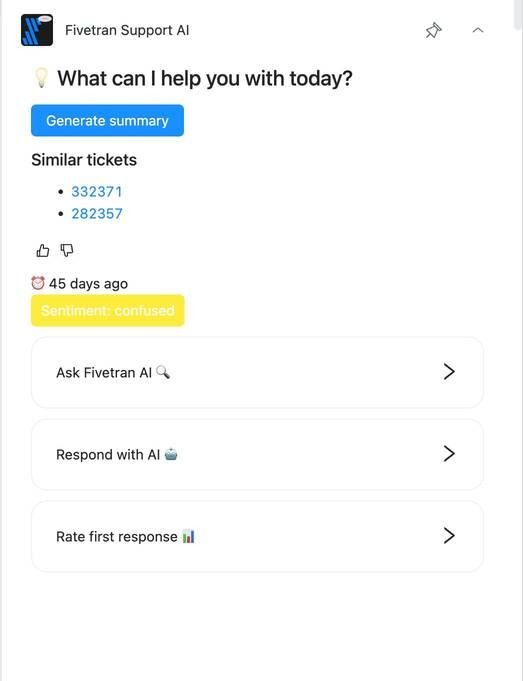
- Generate Summary solves the handover problem directly. For any long-running escalation, or for tickets being redistributed before an engineer goes on leave, the app generates a structured AI summary covering the issue, the troubleshooting steps already taken, and the recommended next actions. What used to take fifteen minutes of careful writing now takes a click.

- Find Similar Tickets surfaces historically resolved tickets that share the same symptoms. Rather than rediscovering a resolution path that a colleague already found three months ago, engineers can see exactly how comparable cases were solved — and reuse what worked.
How this is different from off-the-shelf AI support tools
Most off-the-shelf support tools by outside vendors are built on a shallow knowledge base — public documentation and maybe some FAQs. They work fine for support use cases for simple products. Fivetran's product is not simple.
When a customer opens a ticket about why their BigQuery destination is failing partial row updates during a high-volume sync, the answer might live in a Jira engineering issue, a Slack thread from six months ago between two engineers who no longer work here, a GitHub pull request for a connector-specific fix, and three prior support tickets with different symptoms but the same root cause. No off-the-shelf tool ingests all of that.
Because we built this on our own infrastructure — with connectors pulling structured and unstructured data from all six of those systems into a unified warehouse — the AI actually has the context it needs to generate useful answers.
Data infrastructure is the foundation for AI
The AI in our support tool is only as good as the data underneath it. Without connectors pulling clean, up-to-date information from Zendesk, Slab, Jira, GitHub, Google Drive, Gong, and Salesforce into a unified data lakehouse, and without dbt models transforming that raw data into something an LLM can reason over, the AI would be guessing or hallucinating. Hallucinating at scale is worse than no AI at all.
We already had the infrastructure, pipelines, connectors, data lakehouse, and the transformation layer — those weren't built for this project. They were the same data stack we've been building and advocating for years, repurposed to leverage new advances in AI.
If you're a Zendesk customer using Fivetran and want something similar off the shelf for your own support team, we're making this technology available as part of our AI product offering. Join the waitlist here.
[CTA_MODULE]
Articles associés
Commencer gratuitement
Rejoignez les milliers d’entreprises qui utilisent Fivetran pour centraliser et transformer leur data.










