

Contents
What is data integration architecture?
Why data integration architecture is important
Factors that affect data integration architecture
Data integration architecture best practices
Data integration is a vital part of how companies manage the information they receive from customers, leads and teams within their organization.
Considering how integral adequate data management is, businesses must ensure that their data integration workflows and related processes are efficient.
One way to do this is via data integration architecture, which maps out the primary and secondary systems involved in a workflow, helping the business get a high-level overview of its current processes.
In this article, we’ll explain what data integration architecture is, why businesses need it, the important factors that affect it and the best practices for creating it.
Want to learn more about data integration? This free ebook can help
READ MEWhat is data integration architecture?
Data integration architecture outlines the processes within a data pipeline and how they relate to each other. It defines how data flows in from source systems, where it gets stored and how it’s transformed into usable metrics and analytics.
The modern data pipeline for automated data integration has the following components:
- Data sources
- Automated data pipeline
- Data warehouse or lake
- Transformations
- Business intelligence or data science platform
Efficient data integration solutions and practices streamline data collection, storage and transformation.
Your data integration strategy and architecture depend on your business processes, goals and resources. Most modern companies implement data pipelines based on the Extract, Load, Transform (ELT) data integration method over the older Extract, Transform, Load (ETL) method.
Several other factors also affect your data workflow, but before we delve into those, let’s explore the benefits of using data integration architecture.
Why data integration architecture is important
Data integration architecture helps your team in the following ways.

Let’s take a look.
1. Get a high-level overview
Integration architecture provides a bird’s eye view of how your data is currently moving from its sources to its destinations. You can compare this to how you want the data pipeline to function and implement changes to drive improvement.
By understanding the relationships between different data sets, applications and their use cases, you can design a pipeline that works for your team or organization rather than forcing analysts to make the most of a less efficient workflow.
2. Establish development standards
Data integration architecture helps set development standards that lead to uniform yet adaptable data pipelines throughout the organization.
Establishing standards and setting key pipeline requirements speeds up development and boosts collaboration.
When developers or engineers have to build or modify data elements for different integration projects, having a consistent baseline or source of truth helps.
3. Set overall architectural patterns
Similar to development standards, architectural patterns can be established to quickly create or modify pipelines and workflows.
Having an overall pattern of how servers, interfaces, and transformations interact with each other will give developers a foundation to build data pipelines or workflows that meet project, team and business goals.
4. Provide normalization
Applying unified development standards and architectural patterns helps integrate data from disparate sources while preventing errors and repetition.
This improves data integrity, fosters smooth collaboration, facilitates informed decision-making and boosts innovation.
When analysts and business intelligence (BI) tools have an efficient database to work with, they can identify patterns across data sets and business processes. This improves the quality of the insights they garner.
5. Improve simplicity
Consistent data integration architecture makes applying development standards and patterns to different projects and data workflows easier.
When developers have to build data pipelines from scratch, the architecture acts as a blueprint that they can build upon.
Thus, integration architecture provides simplicity. Developers and engineers can efficiently reuse data pipeline elements — such as transformations and jobs — and integration patterns without impairing data integrity.
Factors that affect data integration architecture
There are five factors that affect the structure of your data integration architecture.

Let’s look at each of these factors in more detail.
1. Storage
Data storage or destinations are at the end of a modern data pipeline. Data warehouses and data lakes are the two most common storage systems.
A data warehouse stores only structured data, while a data lake stores both structured and unstructured data.
Cloud data warehouses are ideal for operational databases, transactional systems and applications that produce structured data. Data lakes are suitable for big data analytics, machine learning and predictive analytics.
The data storage you use affects the structure and workflow of your pipeline.
Organizations that use the ELT framework in their data pipelines use data lakes. Or they use a newer, hybrid storage option called the data lakehouse, which combines the best features of both older storage systems.
2. Cloud-based
A cloud-based data pipeline is the best option for current businesses’ data needs. These pipelines are easier to create and implement, especially when using an automated data integration service like Fivetran.
Compared to data pipelines that rely on on-premise servers and storage, a cloud-based architecture costs less and is more efficient. Cloud data integration updates data in real time rapidly, reduces errors and creates centralized access. This is especially vital for hybrid and remote teams that need instant access to data anytime, anywhere.
Cloud-based data pipelines are also easier to both scale as your business grows and modify when your business needs change.
3. ETL vs. ELT
There are two frameworks for data integration: ETL and ELT. ETL extracts data from sources, applies transformations and loads the data to the destination.
ELT, on the other hand, extracts and loads data before applying transformations.
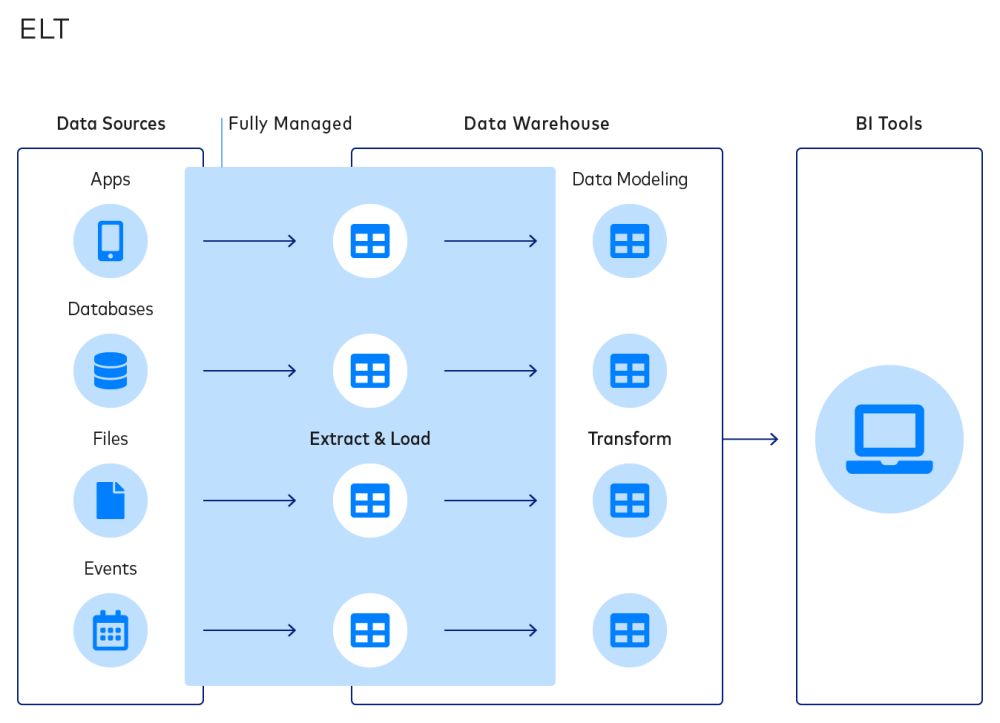
Your data integration architecture can change depending on the framework you choose. Many regard ELT as the future since it simplifies data integration, lowers failure rates, enables workflow automation and facilitates easier outsourcing.
4. Real-time data integration
Real-time data integration is vital for businesses. In our recent survey, 86 percent of companies said that real-time data is “highly valuable” and it’s easy to understand why.
Stale or old data leads to poor decision-making via either insufficient data or delayed data delivery — which decreases revenue.
Current data integration architectures must focus on high-volume data replication using log-based change data capture (CDC). A service like Fivetran can integrate with your cloud data solution to rapidly identify and update record modifications.
This allows for real-time processing and the automation of extraction, loading and validation processes.
5. AI-powered
Most data science and senior IT professionals who participated in our recent survey believe that artificial intelligence is the future and that businesses will need it to survive. However, the lack of automation in data pipelines was a significant roadblock.
While using an automated data pipeline will lead to significant improvement, it’s also essential to focus on infusing artificial intelligence into your data integration system.
AI enables autonomous data integration via machine learning and predictive analytics. It can help businesses reduce their operational costs while improving their work processes and productivity.
Data integration architecture best practices
Creating a data integration architecture that fits your business use case isn’t easy.

Follow these best practices.
1. Cater to business objectives
Design your data integration workflow based on precise business objectives. Integration aims to make your data work for you, not the other way around.
Create pipelines that cater to one or more business goals. If your target is “Goal A,” then consider the specific data and analytical requirements you will need to achieve it. Your data integration will revolve around these criteria.
Modern data stacks enable standardization and easy data replication so that businesses can quickly create pipelines for varying objectives.
Using one pipeline for all your analytical needs can lead to an overload of information. Analysts will have to sift through irrelevant data to get what they need — and this delays insights.
2. Promote easier collaboration
A good data integration architecture removes silos and reduces bottlenecks to boost collaboration.
When building a pipeline, consider that all the data from diverse sources must go through the integration process and land at the same destination while simultaneously avoiding errors and duplicates.
Since the architecture provides a high-level overview, managers and developers can easily identify any problem areas and implement changes to address them quickly.
3. Capitalize on automation
Incorporate AI-powered automation to streamline processes within your data pipeline and create an autonomous integration workflow that records and updates changes in real time.
You can use platforms like Fivetran to automate your entire data pipeline for centralized data collection, accurate insights and easier data sharing between different teams or business processes.
Without automation, businesses are forced to rely on manual change tracking and data transfer, which are far slower and more error-prone.
4. Flexibility
The architecture must focus on creating a cloud-based data pipeline that is easy to scale or modify as needed.
Business requirements and data integration technologies evolve over time. A pipeline that fails to accommodate on-demand changes or breaks down when implementing new technologies is not sustainable.
An inflexible pipeline hinders businesses via slower adoption of new technologies, more complex error correction and additional upgrade costs in the future.
5. Security
Your data pipeline will contain sensitive data from internal and external sources. A leak in business, client or customer data can have severe implications. This is why your pipeline platform has to be fully secure and compliant.
Fivetran, for example, boasts comprehensive privacy and security. Your data is encrypted in transit and rest, personal data is anonymized and there is detailed logging. Businesses also get complete data access control and granular role-based access.
These features, along with secure sign-on and overall transparency, are necessary to keep your data safe.
Conclusion
Data integration architecture dictates how your organization collects and processes data to gain valuable insights. It provides a uniform structure via architectural patterns and developmental standards.
This structure enables businesses to create effective pipelines that cater to their goals. Businesses can use data integration architecture to develop automated cloud-based data pipelines on Fivetran with real-time updates, rapid data processing, easy data sharing and no duplication.
Fivetran also allows easy modifications in case of changes to your integration processes and business growth. Sign up today to see how easy it is to build an excellent data pipeline without any code.














.svg)
.svg)
.svg)